
[ad_1]
Let 

![{H[X]}](https://s0.wp.com/latex.php?latex=%7BH%5BX%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![displaystyle H[X] = -sum_{s in S} {bf P}[X = s] log {bf P}[X = s].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+H%5BX%5D+%3D+-%5Csum_%7Bs+%5Cin+S%7D+%7B%5Cbf+P%7D%5BX+%3D+s%5D+%5Clog+%7B%5Cbf+P%7D%5BX+%3D+s%5D.&bg=ffffff&fg=000000&s=0&c=20201002)
There’s a good variational method that lets one compute logs of sums of exponentials when it comes to this entropy:
Lemma 1 (Gibbs variational method) Let
be a perform. Then
![displaystyle log sum_{s in S} exp(f(s)) = sup_X {bf E} f(X) + {bf H}[X]. (1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Clog+%5Csum_%7Bs+%5Cin+S%7D+%5Cexp%28f%28s%29%29+%3D+%5Csup_X+%7B%5Cbf+E%7D+f%28X%29+%2B+%7B%5Cbf+H%7D%5BX%5D.+%5C+%5C+%5C+%5C+%5C+%281%29&bg=ffffff&fg=000000&s=0&c=20201002)
Proof: Be aware that shifting 



![displaystyle 0 = sup_X sum_{s in S} {bf P}[X = s] log {bf P}[Y = s] -sum_{s in S} {bf P}[X = s] log {bf P}[X = s].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++0+%3D+%5Csup_X+%5Csum_%7Bs+%5Cin+S%7D+%7B%5Cbf+P%7D%5BX+%3D+s%5D+%5Clog+%7B%5Cbf+P%7D%5BY+%3D+s%5D+-%5Csum_%7Bs+%5Cin+S%7D+%7B%5Cbf+P%7D%5BX+%3D+s%5D+%5Clog+%7B%5Cbf+P%7D%5BX+%3D+s%5D.&bg=ffffff&fg=000000&s=0&c=20201002)
However that is exactly the Gibbs inequality. (The expression contained in the supremum may also be written as 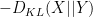
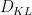



On this word I want to use this variational method (which is also referred to as the Donsker-Varadhan variational method) to offer one other proof of the next inequality of Carbery.
Theorem 2 (Generalized Cauchy-Schwarz inequality) Let
, let
be finite non-empty units, and let
be capabilities for every
. Let
and
be optimistic capabilities for every
the place
is the amount
the place
is the set of all tuples
such that
for
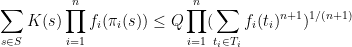

Thus for example, the id is trivial for 

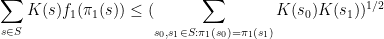

which is well confirmed by Cauchy-Schwarz, whereas for 
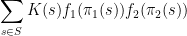
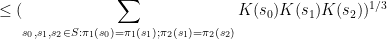

which may also be confirmed by elementary means. Nevertheless even for 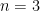

We now show this inequality. We write 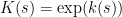
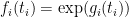

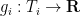
![displaystyle sup_X {bf E} k(X) + sum_{i=1}^n g_i(pi_i(X)) + {bf H}[X]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Csup_X+%7B%5Cbf+E%7D+k%28X%29+%2B+%5Csum_%7Bi%3D1%7D%5En+g_i%28%5Cpi_i%28X%29%29+%2B+%7B%5Cbf+H%7D%5BX%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
![displaystyle leq frac{1}{n+1} sup_{(X_0,dots,X_n)} {bf E} k(X_0)+dots+k(X_n) + {bf H}[X_0,dots,X_n]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cleq+%5Cfrac%7B1%7D%7Bn%2B1%7D+%5Csup_%7B%28X_0%2C%5Cdots%2CX_n%29%7D+%7B%5Cbf+E%7D+k%28X_0%29%2B%5Cdots%2Bk%28X_n%29+%2B+%7B%5Cbf+H%7D%5BX_0%2C%5Cdots%2CX_n%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
![displaystyle + frac{1}{n+1} sum_{i=1}^n sup_{Y_i} (n+1) {bf E} g_i(Y_i) + {bf H}[Y_i]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%2B+%5Cfrac%7B1%7D%7Bn%2B1%7D+%5Csum_%7Bi%3D1%7D%5En+%5Csup_%7BY_i%7D+%28n%2B1%29+%7B%5Cbf+E%7D+g_i%28Y_i%29+%2B+%7B%5Cbf+H%7D%5BY_i%5D&bg=ffffff&fg=000000&s=0&c=20201002)
the place 
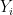
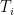
Lemma 3 (Conditional expectation computation) Let
, the place every
has the identical distribution as
![displaystyle {bf H}[X_0,dots,X_n] = (n+1) {bf H}[X]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cbf+H%7D%5BX_0%2C%5Cdots%2CX_n%5D+%3D+%28n%2B1%29+%7B%5Cbf+H%7D%5BX%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
![displaystyle - {bf H}[pi_1(X)] - dots - {bf H}[pi_n(X)].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+-+%7B%5Cbf+H%7D%5B%5Cpi_1%28X%29%5D+-+%5Cdots+-+%7B%5Cbf+H%7D%5B%5Cpi_n%28X%29%5D.&bg=ffffff&fg=000000&s=0&c=20201002)
Proof: We induct on 



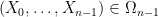
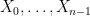
![displaystyle {bf H}[X_0,dots,X_{n-1}] = n {bf H}[X] - {bf H}[pi_1(X)] - dots - {bf H}[pi_{n-1}(X)].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cbf+H%7D%5BX_0%2C%5Cdots%2CX_%7Bn-1%7D%5D+%3D+n+%7B%5Cbf+H%7D%5BX%5D+-+%7B%5Cbf+H%7D%5B%5Cpi_1%28X%29%5D+-+%5Cdots+-+%7B%5Cbf+H%7D%5B%5Cpi_%7Bn-1%7D%28X%29%5D.&bg=ffffff&fg=000000&s=0&c=20201002)
By speculation, 
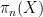
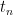

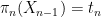
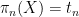
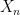

![displaystyle {bf H}[X_0,dots,X_n] = {bf H}[pi_n(X_n)] + {bf H}[X_0,dots,X_n| pi_n(X_n)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%7B%5Cbf+H%7D%5BX_0%2C%5Cdots%2CX_n%5D+%3D+%7B%5Cbf+H%7D%5B%5Cpi_n%28X_n%29%5D+%2B+%7B%5Cbf+H%7D%5BX_0%2C%5Cdots%2CX_n%7C+%5Cpi_n%28X_n%29%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![displaystyle = {bf H}[pi_n(X_n)] + {bf H}[X_0,dots,X_{n-1}| pi_n(X_n)] + {bf H}[X_n| pi_n(X_n)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%3D+%7B%5Cbf+H%7D%5B%5Cpi_n%28X_n%29%5D+%2B+%7B%5Cbf+H%7D%5BX_0%2C%5Cdots%2CX_%7Bn-1%7D%7C+%5Cpi_n%28X_n%29%5D+%2B+%7B%5Cbf+H%7D%5BX_n%7C+%5Cpi_n%28X_n%29%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
![displaystyle = {bf H}[pi_n(X)] + {bf H}[X_0,dots,X_{n-1}| pi_n(X_{n-1})] + {bf H}[X_n| pi_n(X_n)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%3D+%7B%5Cbf+H%7D%5B%5Cpi_n%28X%29%5D+%2B+%7B%5Cbf+H%7D%5BX_0%2C%5Cdots%2CX_%7Bn-1%7D%7C+%5Cpi_n%28X_%7Bn-1%7D%29%5D+%2B+%7B%5Cbf+H%7D%5BX_n%7C+%5Cpi_n%28X_n%29%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
![displaystyle = {bf H}[pi_n(X)] + ({bf H}[X_0,dots,X_{n-1}] - {bf H}[pi_n(X_{n-1})])](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%3D+%7B%5Cbf+H%7D%5B%5Cpi_n%28X%29%5D+%2B+%28%7B%5Cbf+H%7D%5BX_0%2C%5Cdots%2CX_%7Bn-1%7D%5D+-+%7B%5Cbf+H%7D%5B%5Cpi_n%28X_%7Bn-1%7D%29%5D%29+&bg=ffffff&fg=000000&s=0&c=20201002)
![displaystyle + ({bf H}[X_n] - {bf H}[pi_n(X_n)])](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%2B+%28%7B%5Cbf+H%7D%5BX_n%5D+-+%7B%5Cbf+H%7D%5B%5Cpi_n%28X_n%29%5D%29+&bg=ffffff&fg=000000&s=0&c=20201002)
![displaystyle ={bf H}[X_0,dots,X_{n-1}] + {bf H}[X_n] - {bf H}[pi_n(X_n)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%3D%7B%5Cbf+H%7D%5BX_0%2C%5Cdots%2CX_%7Bn-1%7D%5D+%2B+%7B%5Cbf+H%7D%5BX_n%5D+-+%7B%5Cbf+H%7D%5B%5Cpi_n%28X_n%29%5D&bg=ffffff&fg=000000&s=0&c=20201002)
and the declare now follows from the induction speculation.
With somewhat extra effort, one can exchange
[ad_2]