
[ad_1]
Model 14.0 of Wolfram Language and Mathematica is accessible instantly each on the desktop and within the cloud. See additionally extra detailed info on Model 13.1, Model 13.2 and Model 13.3.
Constructing One thing Larger and Larger… for 35 Years and Counting
In the present day we have a good time a brand new waypoint on our journey of almost 4 a long time with the discharge of Model 14.0 of Wolfram Language and Mathematica. Over the 2 years since we launched Model 13.0 we’ve been steadily delivering the fruits of our analysis and improvement in .1 releases each six months. In the present day we’re aggregating these—and extra—into Model 14.0.
It’s been greater than 35 years now since we launched Model 1.0. And all these years we’ve been persevering with to construct a taller and taller tower of capabilities, progressively increasing the scope of our imaginative and prescient and the breadth of our computational protection of the world:

Model 1.0 had 554 built-in features; in Model 14.0 there are 6602. And behind every of these features is a narrative. Typically it’s a narrative of making a superalgorithm that encapsulates a long time of algorithmic improvement. Typically it’s a narrative of painstakingly curating information that’s by no means been assembled earlier than. Typically it’s a narrative of drilling right down to the essence of one thing to invent new approaches and new features that may seize it.
And from all these items we’ve been steadily constructing the coherent complete that’s right now’s Wolfram Language. Within the arc of mental historical past it defines a broad, new, computational paradigm for formalizing the world. And at a sensible stage it offers a superpower for implementing computational considering—and enabling “computational X” for all fields X.
To us it’s profoundly satisfying to see what has been finished over the previous three a long time with the whole lot we’ve constructed to date. So many discoveries, so many innovations, a lot achieved, a lot discovered. And seeing this helps drive ahead our efforts to sort out nonetheless extra, and to proceed to push each boundary we are able to with our R&D, and to ship the leads to new variations of our system.
Our R&D portfolio is broad. From initiatives that get accomplished inside months of their conception, to initiatives that depend on years (and generally even a long time) of systematic improvement. And key to the whole lot we do is leveraging what we’ve got already finished—typically taking what in earlier years was a pinnacle of technical achievement, and now utilizing it as a routine constructing block to achieve a stage that might barely even be imagined earlier than. And past sensible expertise, we’re additionally regularly going additional and additional in leveraging what’s now the huge conceptual framework that we’ve been constructing all these years—and progressively encapsulating it within the design of the Wolfram Language.
We’ve labored laborious all these years not solely to create concepts and expertise, but in addition to craft a sensible and sustainable ecosystem wherein we are able to systematically do that now and into the long-term future. And we proceed to innovate in these areas, broadening the supply of what we’ve inbuilt new and other ways, and thru new and totally different channels. And prior to now 5 years we’ve additionally been in a position to open up our core design course of to the world—frequently livestreaming what we’re doing in a uniquely open method.
And certainly over the previous a number of years the seeds of basically the whole lot we’re delivering right now in Model 14.0 has been overtly shared with the world, and represents an achievement not just for our inside groups but in addition for the many individuals who’ve participated in and commented on our livestreams.
A part of what Model 14.0 is about is constant to develop the area of our computational language, and our computational formalization of the world. However Model 14.0 can also be about streamlining and sharpening the performance we’ve already outlined. All through the system there are issues we’ve made extra environment friendly, extra strong and extra handy. And, sure, in advanced software program, bugs of many varieties are a theoretical and sensible inevitability. And in Model 14.0 we’ve fastened almost 10,000 bugs, the bulk discovered by our more and more subtle inside software program testing strategies.
Now We Have to Inform the World
Even after all of the work we’ve put into the Wolfram Language over the previous a number of a long time, there’s nonetheless one more problem: the right way to let folks know simply what the Wolfram Language can do. Again after we launched Model 1.0 I used to be in a position to write a ebook of manageable dimension that might just about clarify the entire system. However for Model 14.0—with all of the performance it accommodates—one would want a ebook with maybe 200,000 pages.
And at this level no one (even me!) instantly is aware of the whole lot the Wolfram Language does. In fact certainly one of our nice achievements has been to take care of throughout all that performance a tightly coherent and constant design that leads to there finally being solely a small set of basic ideas to study. However on the huge scale of the Wolfram Language because it exists right now, figuring out what’s doable—and what can now be formulated in computational phrases—is inevitably very difficult. And all too typically after I present folks what’s doable, I’ll get the response “I had no thought the Wolfram Language may do that!”
So prior to now few years we’ve put growing emphasis into constructing large-scale mechanisms to clarify the Wolfram Language to folks. It begins at a really fine-grained stage, with “just-in-time info” supplied, for instance, by way of ideas made whenever you kind. Then for every operate (or different assemble within the language) there are pages that designate the operate, with in depth examples. And now, more and more, we’re including “just-in-time studying materials” that leverages the concreteness of the features to supply self-contained explanations of the broader context of what they do.
By the best way, in fashionable occasions we have to clarify the Wolfram Language not simply to people, but in addition to AIs—and our very in depth documentation and examples have proved extraordinarily useful in coaching LLMs to make use of the Wolfram Language. And for AIs we’re offering a wide range of instruments—like quick computable entry to documentation, and computable error dealing with. And with our Chat Pocket book expertise there’s additionally a brand new “on ramp” for creating Wolfram Language code from linguistic (or visible, and so on.) enter.
However what in regards to the greater image of the Wolfram Language? For each folks and AIs it’s essential to have the ability to clarify issues at a better stage, and we’ve been doing an increasing number of on this course. For greater than 30 years we’ve had “information pages” that summarize particular performance particularly areas. Now we’re including “core space pages” that give a broader image of enormous areas of performance—every one in impact protecting what may in any other case be a complete product by itself, if it wasn’t simply an built-in a part of the Wolfram Language:

However we’re going even a lot additional, constructing complete programs and books that present fashionable hands-on Wolfram-Language-enabled introductions to a broad vary of areas. We’ve now lined the fabric of many commonplace faculty programs (and quite a bit in addition to), in a brand new and really efficient “computational” method, that permits quick, sensible engagement with ideas:

All these programs contain not solely lectures and notebooks but in addition auto-graded workouts, in addition to official certifications. And we’ve got an everyday calendar of everyone-gets-together-at-the-same-time instructor-led peer Research Teams about these programs. And, sure, our Wolfram U operation is now rising as a major academic entity, with many hundreds of scholars at any given time.
Along with complete programs, we’ve got “miniseries” of lectures about particular subjects:

And we even have programs—and books—in regards to the Wolfram Language itself, like my Elementary Introduction to the Wolfram Language, which got here out in a 3rd version this 12 months (and has an related course, on-line model, and so on.):

In a considerably totally different course, we’ve expanded our Wolfram Summer time Faculty so as to add a Wolfram Winter Faculty, and we’ve enormously expanded our our Wolfram Excessive Faculty
Summer time Analysis Program, including year-round applications, middle-school applications, and so on.—together with the brand new “Computational Adventures” weekly exercise program.
After which there’s livestreaming. We’ve been doing weekly “R&D livestreams” with our improvement workforce (and generally additionally exterior company). And I personally have additionally been doing numerous livestreaming (232 hours of it in 2023 alone)—a few of it design critiques of Wolfram Language performance, and a few of it answering questions, technical and different.
The checklist of the way we’re getting the phrase out in regards to the Wolfram Language goes on. There’s Wolfram Neighborhood, that’s stuffed with attention-grabbing contributions, and has ever-increasing readership. There are websites like Wolfram Challenges. There are our Wolfram Expertise Conferences. And plenty extra.
We’ve put immense effort into constructing the entire Wolfram expertise stack over the previous 4 a long time. And whilst we proceed to aggressively construct it, we’re placing an increasing number of effort into telling the world about simply what’s in it, and serving to folks (and AIs) to make the simplest use of it. However in a way, the whole lot we’re doing is only a seed for what the broader group of Wolfram Language customers are doing, and may do. Spreading the ability of the Wolfram Language to an increasing number of folks and areas.
The LLMs Have Landed
The machine studying superfunctions Classify and Predict first appeared in Wolfram Language in 2014 (Model 10). By the following 12 months there have been beginning to be features like ImageIdentify and LanguageIdentify, and inside a few years we’d launched our complete neural internet framework and Neural Internet Repository. Included in that had been a wide range of neural nets for language modeling, that allowed us to construct out features like SpeechRecognize and an experimental model of FindTextualAnswer. However—like everybody else—we had been taken without warning on the finish of 2022 by ChatGPT and its exceptional capabilities.
In a short time we realized {that a} main new use case—and market—had arrived for Wolfram|Alpha and Wolfram Language. For now it was not solely people who’d want the instruments we’d constructed; it was additionally AIs. By March 2023 we’d labored with OpenAI to make use of our Wolfram Cloud expertise to ship a plugin to ChatGPT that permits it to name Wolfram|Alpha and Wolfram Language. LLMs like ChatGPT present exceptional new capabilities in reproducing human language, fundamental human considering and normal commonsense information. However—like unaided people—they’re not set as much as take care of detailed computation or exact information. For that, like people, they’ve to make use of formalism and instruments. And the exceptional factor is that the formalism and instruments we’ve inbuilt Wolfram Language (and Wolfram|Alpha) are mainly a broad, good match for what they want.
We created the Wolfram Language to supply a bridge from what people take into consideration to what computation can categorical and implement. And now that’s what the AIs can use as nicely. The Wolfram Language offers a medium not just for people to “assume computationally” but in addition for AIs to take action. And we’ve been steadily doing the engineering to let AIs name on Wolfram Language as simply as doable.
However along with LLMs utilizing Wolfram Language, there’s additionally now the potential of Wolfram Language utilizing LLMs. And already in June 2023 (Model 13.3) we launched a serious assortment of LLM-based capabilities in Wolfram Language. One class is LLM features, that successfully use LLMs as “inside algorithms” for operations in Wolfram Language:
In typical Wolfram Language style, we’ve got a symbolic illustration for LLMs: LLMConfiguration[…] represents an LLM with its varied parameters, promptings, and so on. And prior to now few months we’ve been steadily including connections to the complete vary of widespread LLMs, making Wolfram Language a singular hub not just for LLM utilization, but in addition for learning the efficiency—and science—of LLMs.
You’ll be able to outline your individual LLM features in Wolfram Language. However there’s additionally the Wolfram Immediate Repository that performs the same position for LLM features because the Wolfram Operate Repository does for extraordinary Wolfram Language features. There’s a public Immediate Repository that to date has a number of hundred curated prompts. But it surely’s additionally doable for anybody to put up their prompts within the Wolfram Cloud and make them publicly (or privately) accessible. The prompts can outline personas (“discuss like a [stereotypical] pirate”). They’ll outline AI-oriented features (“write it with emoji”). They usually can outline modifiers that have an effect on the type of output (“haiku type”).

Along with calling LLMs “programmatically” inside Wolfram Language, there’s the brand new idea (first launched in Model 13.3) of “Chat Notebooks”. Chat Notebooks signify a brand new sort of consumer interface, that mixes the graphical, computational and doc options of conventional Wolfram Notebooks with the brand new linguistic interface capabilities delivered to us by LLMs.
The fundamental thought of a Chat Pocket book—as launched in Model 13.3, and now prolonged in Model 14.0—is you could have “chat cells” (requested by typing ‘) whose content material will get despatched to not the Wolfram kernel, however as a substitute to an LLM:

You should utilize “operate prompts”—say from the Wolfram Immediate Repository—immediately in a Chat Pocket book:

And as of Model 14.0 it’s also possible to knit Wolfram Language computations immediately into your “dialog” with the LLM:

(You kind to insert Wolfram Language, very very like the best way you need to use <* … *> to insert Wolfram Language into exterior analysis cells.)
One factor about Chat Notebooks is that—as their title suggests—they are surely centered round “chatting”, and round having a sequential interplay with an LLM. In an extraordinary pocket book, it doesn’t matter the place within the pocket book every Wolfram Language analysis is requested; all that’s related is the order wherein the Wolfram kernel does the evaluations. However in a Chat Pocket book the “LLM evaluations” are at all times a part of a “chat” that’s explicitly specified by the pocket book.
A key a part of Chat Notebooks is the idea of a chat block: kind ~ and also you get a separator within the pocket book that “begins a brand new chat”:

Chat Notebooks—with all their typical Wolfram Pocket book modifying, structuring, automation, and so on. capabilities—are very highly effective simply as “LLM interfaces”. However there’s one other dimension as nicely, enabled by LLMs with the ability to name Wolfram Language as a software.
At one stage, Chat Notebooks present an “on ramp” for utilizing Wolfram Language. Wolfram|Alpha—and much more so, Wolfram|Alpha Pocket book Version—allow you to ask questions in pure language, then have the questions translated into Wolfram Language, and solutions computed. However in Chat Notebooks you possibly can transcend asking particular questions. As a substitute, by way of the LLM, you possibly can simply “begin chatting” about what you need to do, then have Wolfram Language code generated, and executed:

The workflow is usually as follows. First, it’s important to conceptualize in computational phrases what you need. (And, sure, that step requires computational considering—which is a vital talent that too few folks have to date discovered.) Then you definitely inform the LLM what you need, and it’ll attempt to write Wolfram Language code to realize it. It’ll sometimes run the code for you (however it’s also possible to at all times do it your self)—and you may see whether or not you bought what you wished. However what’s essential is that Wolfram Language is meant to be learn not solely by computer systems but in addition by people. And significantly since LLMs truly often appear to handle to put in writing fairly good Wolfram Language code, you possibly can count on to learn what they wrote, and see if it’s what you wished. Whether it is, you possibly can take that code, and use it as a “stable constructing block” for no matter bigger system you is likely to be making an attempt to arrange. In any other case, you possibly can both repair it your self, or attempt chatting with the LLM to get it to do it.
One of many issues we see within the instance above is the LLM—throughout the Chat Pocket book—making a “software name”, right here to a Wolfram Language evaluator. Within the Wolfram Language there’s now a complete mechanism for outlining instruments for LLMs—with every software being represented by an LLMTool symbolic object. In Model 14.0 there’s an experimental model of the brand new Wolfram LLM Software Repository with some predefined instruments:

In a default Chat Pocket book, the LLM has entry to some default instruments, which embody not solely the Wolfram Language evaluator, but in addition issues like Wolfram documentation search and Wolfram|Alpha question. And it’s frequent to see the LLM travel making an attempt to put in writing “code that works”, and for instance generally having to “resort” (very like people do) to studying the documentation.
One thing that’s new in Model 14.0 is experimental entry to multimodal LLMs that may take photos in addition to textual content as enter. And when this functionality is enabled, it permits the LLM to “take a look at footage from the code it generated”, see in the event that they’re what was requested for, and doubtlessly right itself:

The deep integration of photos into Wolfram Language—and Wolfram Notebooks—yields all kinds of prospects for multimodal LLMs. Right here we’re giving a plot as a picture and asking the LLM the right way to reproduce it:

One other course for multimodal LLMs is to take information (within the a whole bunch of codecs accepted by Wolfram Language) and use the LLM to information its visualization and evaluation within the Wolfram Language. Right here’s an instance that begins from a file information.csv within the present listing in your laptop:

One factor that’s very good about utilizing Wolfram Language immediately is that the whole lot you do (nicely, except you utilize RandomInteger, and so on.) is totally reproducible; do the identical computation twice and also you’ll get the identical end result. That’s not true with LLMs (no less than proper now). And so when one makes use of LLMs it appears like one thing extra ephemeral and fleeting than utilizing Wolfram Language. One has to seize any good outcomes one will get—as a result of one may by no means be capable to reproduce them. Sure, it’s very useful that one can retailer the whole lot in a Chat Pocket book, even when one can’t rerun it and get the identical outcomes. However the extra “everlasting” use of LLM outcomes tends to be “offline”. Use an LLM “up entrance” to determine one thing out, then simply use the end result it gave.
One surprising software of LLMs for us has been in suggesting names of features. With the LLM’s “expertise” of what folks speak about, it’s in place to counsel features that individuals may discover helpful. And, sure, when it writes code it has a behavior of hallucinating such features. However in Model 14.0 we’ve truly added one operate—DigitSum—that was steered to us by LLMs. And in the same vein, we are able to count on LLMs to be helpful in making connections to exterior databases, features, and so on. The LLM “reads the documentation”, and tries to put in writing Wolfram Language “glue” code—which then might be reviewed, checked, and so on., and if it’s proper, can be utilized henceforth.
Then there’s information curation, which is a area that—by way of Wolfram|Alpha and lots of of our different efforts—we’ve turn into extraordinarily professional at over the previous couple of a long time. How a lot can LLMs assist with that? They actually don’t “clear up the entire drawback”, however integrating them with the instruments we have already got has allowed us over the previous 12 months to hurry up a few of our information curation pipelines by components of two or extra.
If we take a look at the entire stack of expertise and content material that’s within the fashionable Wolfram Language, the overwhelming majority of it isn’t helped by LLMs, and isn’t prone to be. However there are various—generally surprising—corners the place LLMs can dramatically enhance heuristics or in any other case clear up issues. And in Model 14.0 there are beginning to be all kinds of “LLM inside” features.
An instance is TextSummarize, which is a operate we’ve thought of including for a lot of variations—however now, due to LLMs, can lastly implement to a helpful stage:

The primary LLMs that we’re utilizing proper now are based mostly on exterior companies. However we’re constructing capabilities to permit us to run LLMs in native Wolfram Language installations as quickly as that’s technically possible. And one functionality that’s truly a part of our mainline machine studying effort is NetExternalObject—a method of representing symbolically an externally outlined neural internet that may be run inside Wolfram Language. NetExternalObject permits you, for instance, to take any community in ONNX kind and successfully deal with it as a element in a Wolfram Language neural internet. Right here’s a community for picture depth estimation—that we’re right here importing from an exterior repository (although on this case there’s truly a related community already within the Wolfram Neural Internet Repository):

Now we are able to apply this imported community to a picture that’s been encoded with our built-in picture encoder—then we’re taking the end result and visualizing it:

It’s typically very handy to have the ability to run networks regionally, however it might generally take fairly high-end {hardware} to take action. For instance, there’s now a operate within the Wolfram Operate Repository that does picture synthesis solely regionally—however to run it, you do want a GPU with no less than 8 GB of VRAM:

By the best way, based mostly on LLM ideas (and concepts like transformers) there’ve been different associated advances in machine studying which have been strengthening a complete vary of Wolfram Language areas—with one instance being picture segmentation, the place ImageSegmentationComponents now offers strong “content-sensitive” segmentation:

Nonetheless Going Sturdy on Calculus
When Mathematica 1.0 was launched in 1988, it was a “wow” that, sure, now one may routinely do integrals symbolically by laptop. And it wasn’t lengthy earlier than we acquired to the purpose—first with indefinite integrals, and later with particular integrals—the place what’s now the Wolfram Language may do integrals higher than any human. So did that imply we had been “completed” with calculus? Effectively, no. First there have been differential equations, and partial differential equations. And it took a decade to get symbolic ODEs to a beyond-human stage. And with symbolic PDEs it took till only a few years in the past. Someplace alongside the best way we constructed out discrete calculus, asymptotic expansions and integral transforms. And we additionally applied numerous particular options wanted for functions like statistics, likelihood, sign processing and management idea. However even now there are nonetheless frontiers.
And in Model 14 there are vital advances round calculus. One class issues the construction of solutions. Sure, one can have a formulation that accurately represents the answer to a differential equation. However is it in the perfect, easiest or most helpful kind? Effectively, in Model 14 we’ve labored laborious to ensure it’s—typically dramatically decreasing the scale of expressions that get generated.
One other advance has to do with increasing the vary of “pre-packaged” calculus operations. We’ve been in a position to do derivatives ever since Model 1.0. However in Model 14 we’ve added implicit differentiation. And, sure, one can provide a fundamental definition for this simply sufficient utilizing extraordinary differentiation and equation fixing. However by including an express ImplicitD we’re packaging all that up—and dealing with the tough nook instances—in order that it turns into routine to make use of implicit differentiation wherever you need:

One other class of pre-packaged calculus operations new in Model 14 are ones for vector-based integration. These had been at all times doable to do in a “do-it-yourself” mode. However in Model 14 they’re now streamlined built-in features—that, by the best way, additionally cowl nook instances, and so on. And what made them doable is definitely a improvement in one other space: our decade-long mission so as to add geometric computation to Wolfram Language—which gave us a pure method to describe geometric constructs equivalent to curves and surfaces:

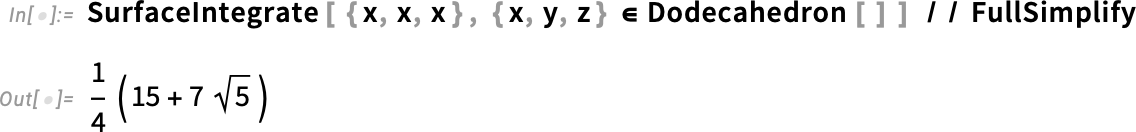
Associated performance new in Model 14 is ContourIntegrate:

Features like ContourIntegrate simply “get the reply”. But when one’s studying or exploring calculus it’s typically additionally helpful to have the ability to do issues in a extra step-by-step method. In Model 14 you can begin with an inactive integral

and explicitly do operations like altering variables:

Typically precise solutions get expressed in inactive kind, significantly as infinite sums:

And now in Model 14 the operate TruncateSum permits you to take such a sum and generate a truncated “approximation”:

Features like D and Combine—in addition to LineIntegrate and SurfaceIntegrate—are, in a way, “traditional calculus”, taught and used for greater than three centuries. However in Model 14 we additionally help what we are able to consider as “rising” calculus operations, like fractional differentiation:

Core Language
What are the primitives from which we are able to greatest construct our conception of computation? That’s at some stage the query I’ve been asking for greater than 4 a long time, and what’s decided the features and buildings on the core of the Wolfram Language.
And because the years go by, and we see an increasing number of of what’s doable, we acknowledge and invent new primitives that can be helpful. And, sure, the world—and the methods folks work together with computer systems—change too, opening up new prospects and bringing new understanding of issues. Oh, and this 12 months there are LLMs which may “get the mental sense of the world” and counsel new features that may match into the framework we’ve created with the Wolfram Language. (And, by the best way, there’ve additionally been numerous nice ideas made by the audiences of our design evaluation livestreams.)
One new assemble added in Model 13.1—and that I personally have discovered very helpful—is Threaded. When a operate is listable—as Plus is—the highest ranges of lists get mixed:
However generally you need one checklist to be “threaded into” the opposite on the lowest stage, not the very best. And now there’s a method to specify that, utilizing Threaded:
In a way, Threaded is a part of a brand new wave of symbolic constructs which have “ambient results” on lists. One quite simple instance (launched in 2015) is Nothing:
One other, launched in 2020, is Splice:
An previous chestnut of Wolfram Language design issues the best way infinite analysis loops are dealt with. And in Model 13.2 we launched the symbolic assemble TerminatedEvaluation to supply higher definition of how out-of-control evaluations have been terminated:

In a curious connection, within the computational illustration of physics in our current Physics Undertaking, the direct analog of nonterminating evaluations are what make doable the seemingly endless universe wherein we dwell.
However what is definitely happening “inside an analysis”, terminating or not? I’ve at all times wished illustration of this. And in reality again in Model 2.0 we launched Hint for this goal:
However simply how a lot element of what the evaluator does ought to one present? Again in Model 2.0 we launched the choice TraceOriginal that traces each path adopted by the evaluator:
However typically that is method an excessive amount of. And in Model 14.0 we’ve launched the brand new setting TraceOriginal→Automated, which doesn’t embody in its output evaluations that don’t do something:
This may occasionally appear pedantic, however when one has an expression of any substantial dimension, it’s a vital piece of pruning. So, for instance, right here’s a graphical illustration of a easy arithmetic analysis, with TraceOriginal→True:

And right here’s the corresponding “pruned” model, with TraceOriginal→Automated:

(And, sure, the buildings of those graphs are carefully associated to issues just like the causal graphs we assemble in our Physics Undertaking.)
Within the effort so as to add computational primitives to the Wolfram Language, two new entrants in Model 14.0 are Comap and ComapApply. The operate Map takes a operate f and “maps it” over a listing:
Comap does the “mathematically co-” model of this, taking a listing of features and “comapping” them onto a single argument:
Why is this convenient? For example, one may need to apply three totally different statistical features to a single checklist. And now it’s straightforward to try this, utilizing Comap:

By the best way, as with Map, there’s additionally an operator kind for Comap:

Comap works nicely when the features it’s coping with take only one argument. If one has features that take a number of arguments, ComapApply is what one sometimes desires:
Speaking of “co-like” features, a brand new operate added in Model 13.2 is PositionSmallest. Min provides the smallest component in a listing; PositionSmallest as a substitute says the place the smallest components are:
One of many essential aims within the Wolfram Language is to have as a lot as doable “simply work”. Once we launched Model 1.0 strings might be assumed simply to include extraordinary ASCII characters, or maybe to have an exterior character encoding outlined. And, sure, it might be messy to not know “throughout the string itself” what characters had been purported to be there. And by the point of Model 3.0 in 1996 we’d turn into contributors to, and early adopters of, Unicode, which supplied a regular encoding for “16-bits’-worth” of characters. And for a few years this served us nicely. However in time—and significantly with the expansion of emoji—16 bits wasn’t sufficient to encode all of the characters folks wished to make use of. So a number of years in the past we started rolling out help for 32-bit Unicode, and in Model 13.1 we built-in it into notebooks—in impact making strings one thing a lot richer than earlier than:
And, sure, you need to use Unicode in all places now:

Video as a Elementary Object
Again when Model 1.0 was launched, a megabyte was numerous reminiscence. However 35 years later we routinely take care of gigabytes. And one of many issues that makes sensible is computation with video. We first launched Video experimentally in Model 12.1 in 2020. And over the previous three years we’ve been systematically broadening and strengthening our potential to take care of video in Wolfram Language. Most likely the one most essential advance is that issues round video now—as a lot as doable—“simply work”, with out “creaking” underneath the pressure of dealing with such massive quantities of knowledge.
We will immediately seize video into notebooks, and we are able to robustly play video wherever inside a pocket book. We’ve additionally added choices for the place to retailer the video in order that it’s conveniently accessible to you and anybody else you need to give entry to it.
There’s numerous complexity within the encoding of video—and we now robustly and transparently help greater than 500 codecs. We additionally do numerous handy issues routinely, like rotating portrait-mode movies—and with the ability to apply picture processing operations like ImageCrop throughout complete movies. In each model, we’ve been additional optimizing the pace of some video operation or one other.
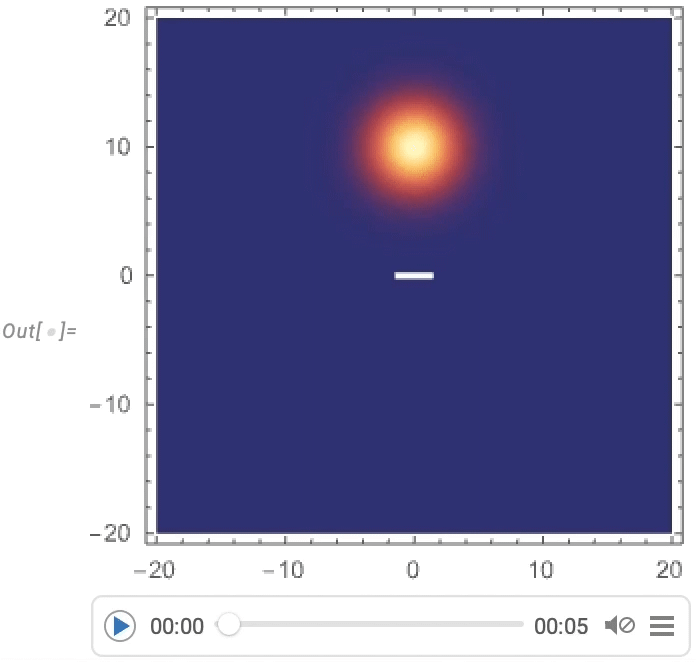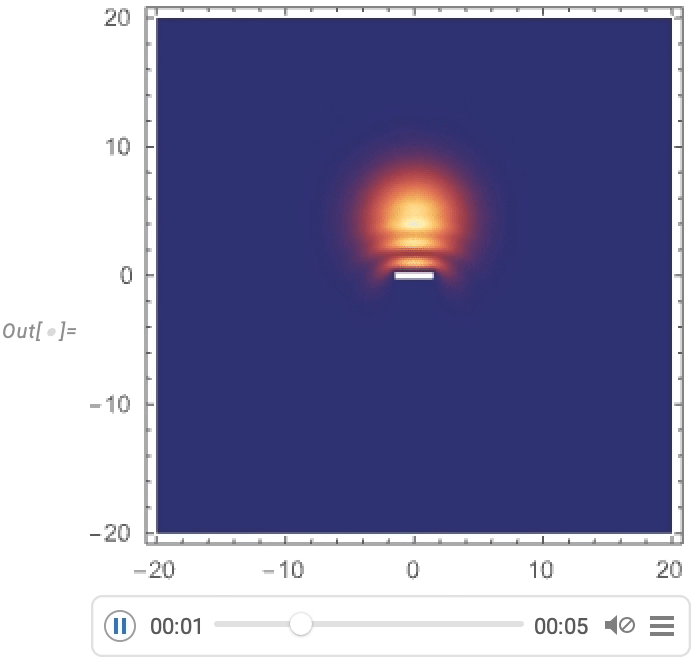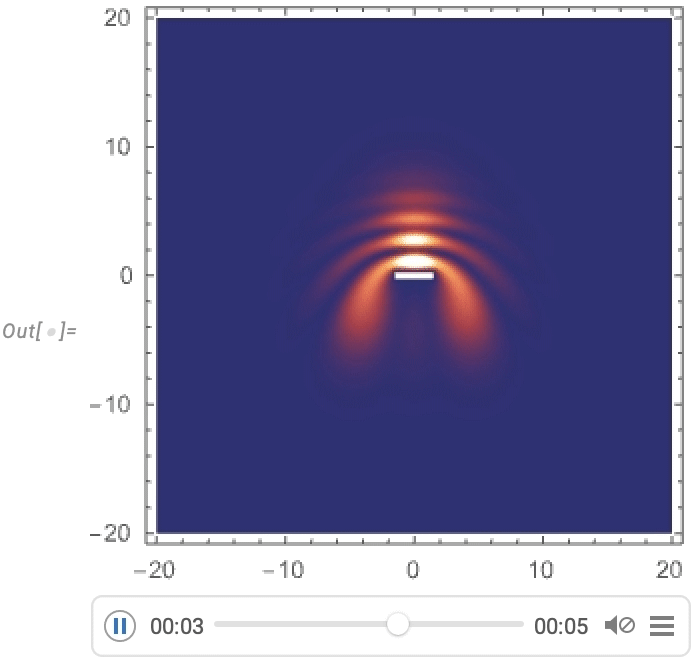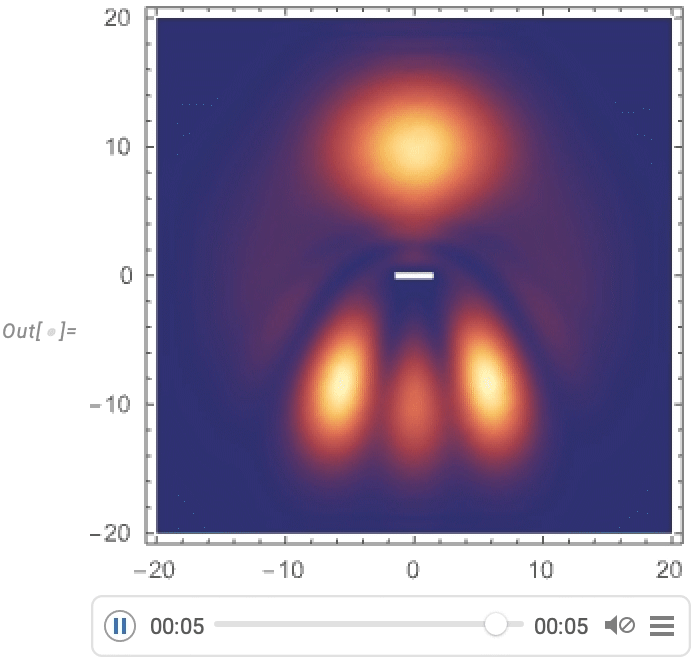
However a very huge focus has been on video turbines: programmatic methods to supply movies and animations. One fundamental instance is AnimationVideo, which produces the identical sort of output as Animate, however as a Video object that may both be displayed immediately in a pocket book, or exported in MP4 or another format:

AnimationVideo relies on computing every body in a video by evaluating an expression. One other class of video turbines take an current visible assemble, and easily “tour” it. TourVideo “excursions” photos, graphics and geo graphics; Tour3DVideo (new in Model 14.0) excursions 3D geometry:

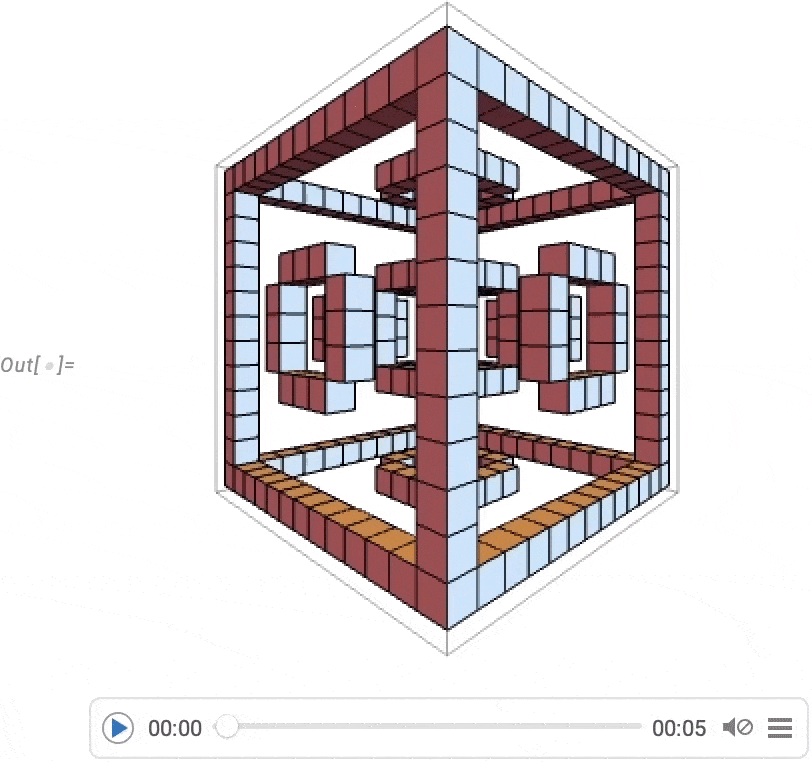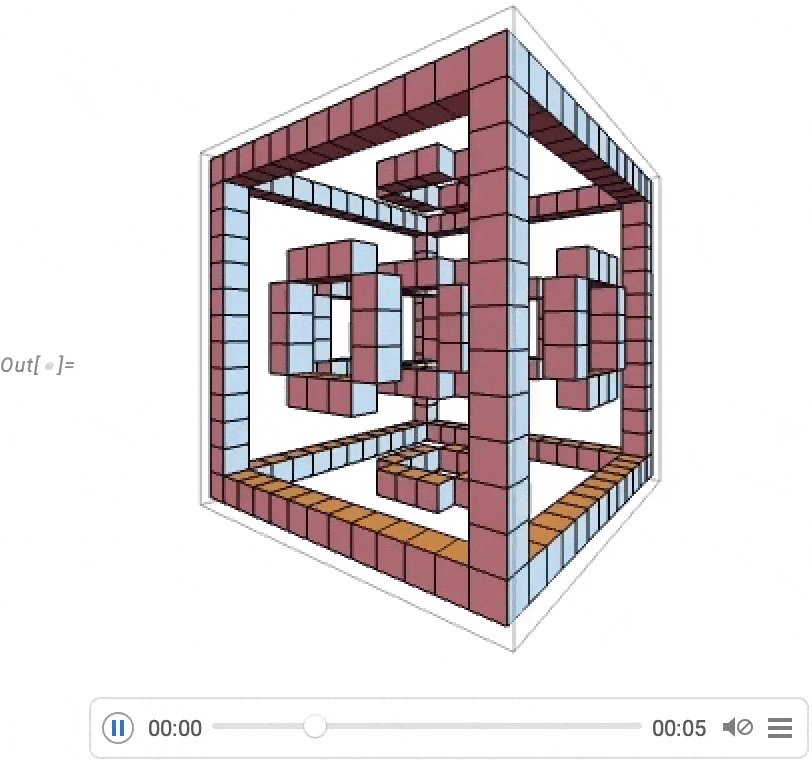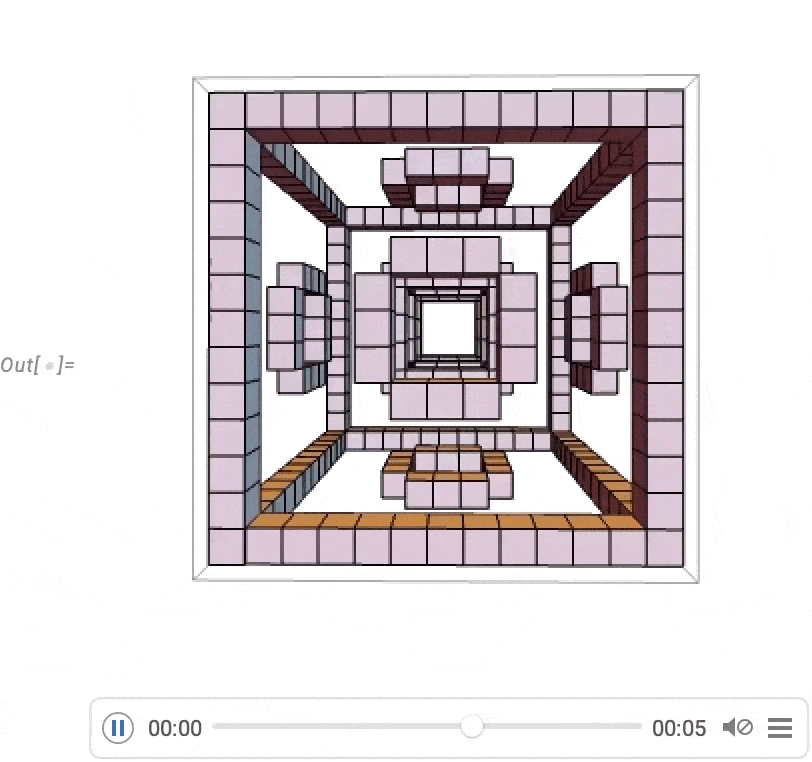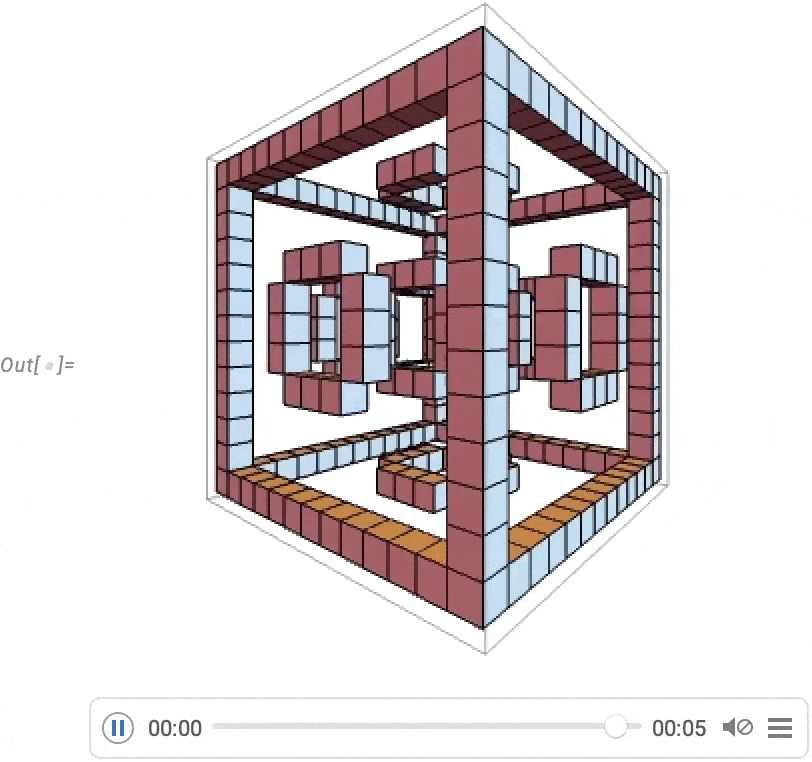
A really highly effective functionality in Wolfram Language is with the ability to apply arbitrary features to movies. One instance of how this may be finished is VideoFrameMap, which maps a operate throughout frames of a video, and which was made environment friendly in Model 13.2:
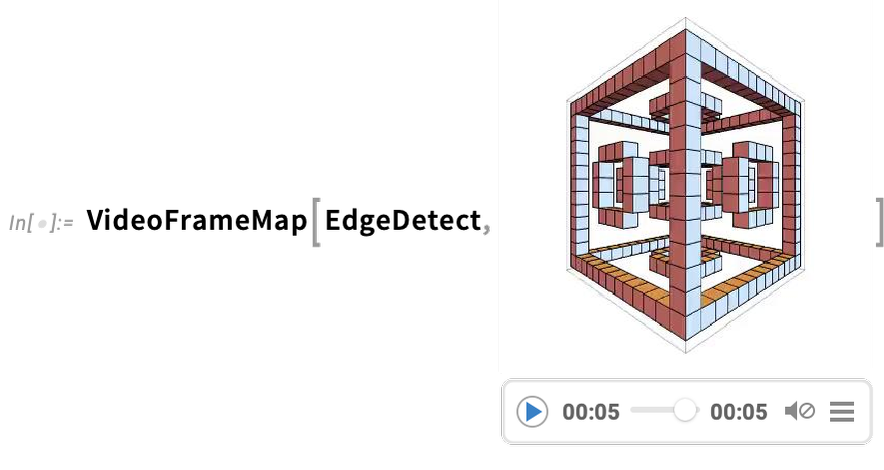
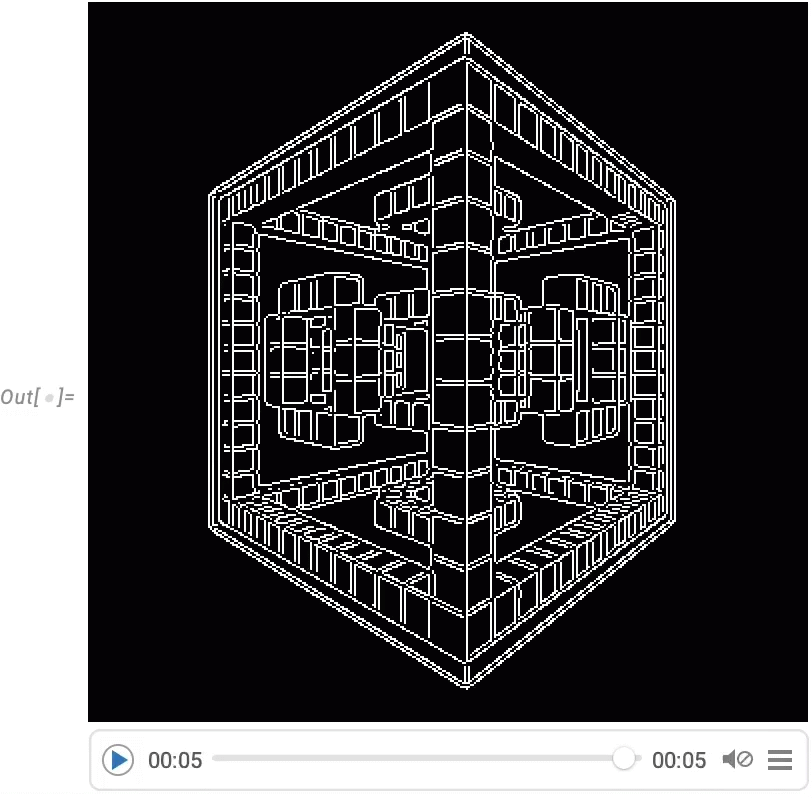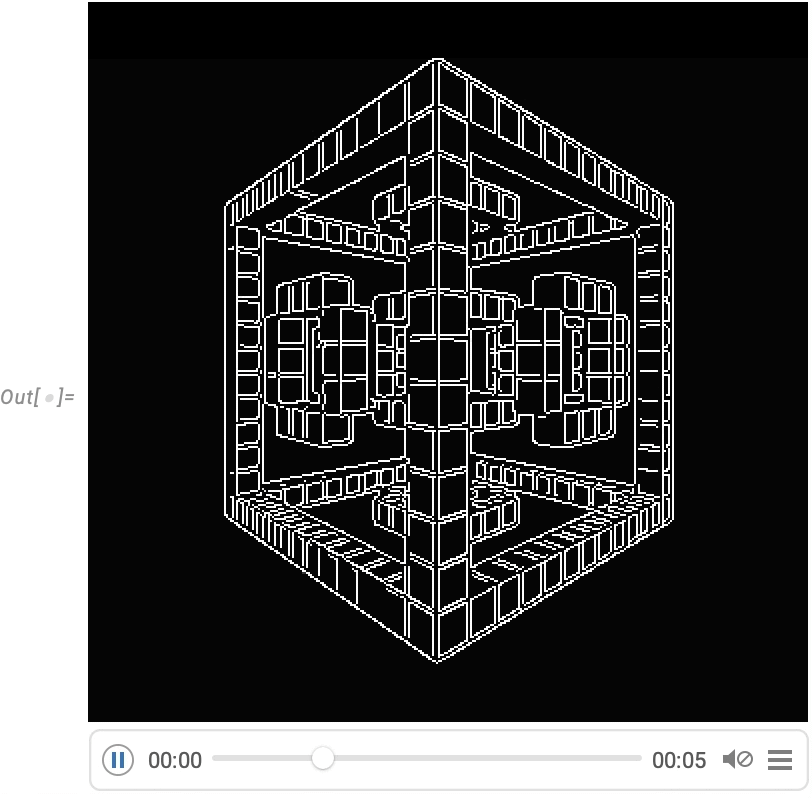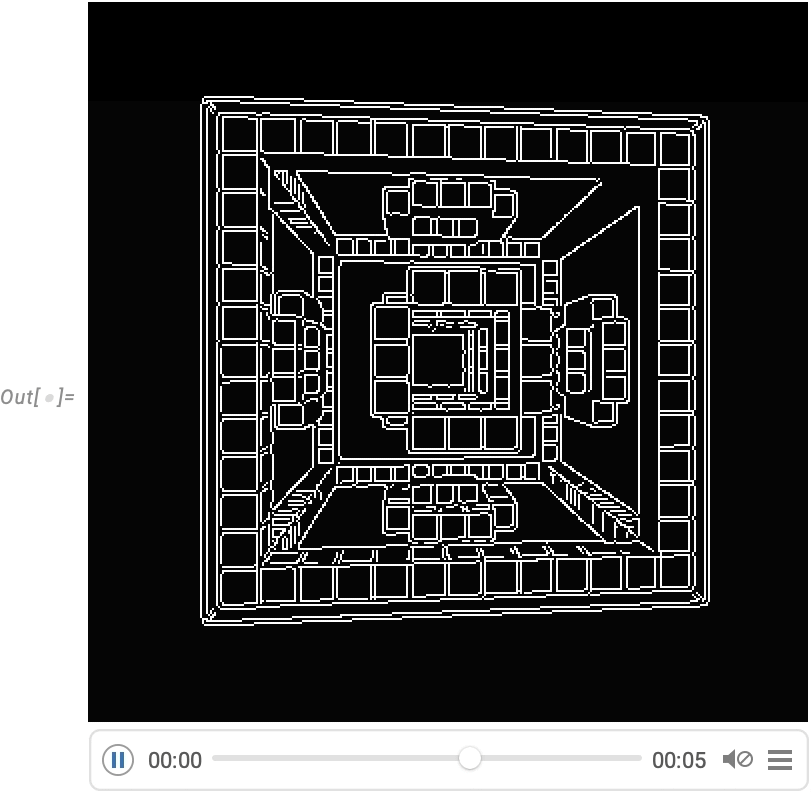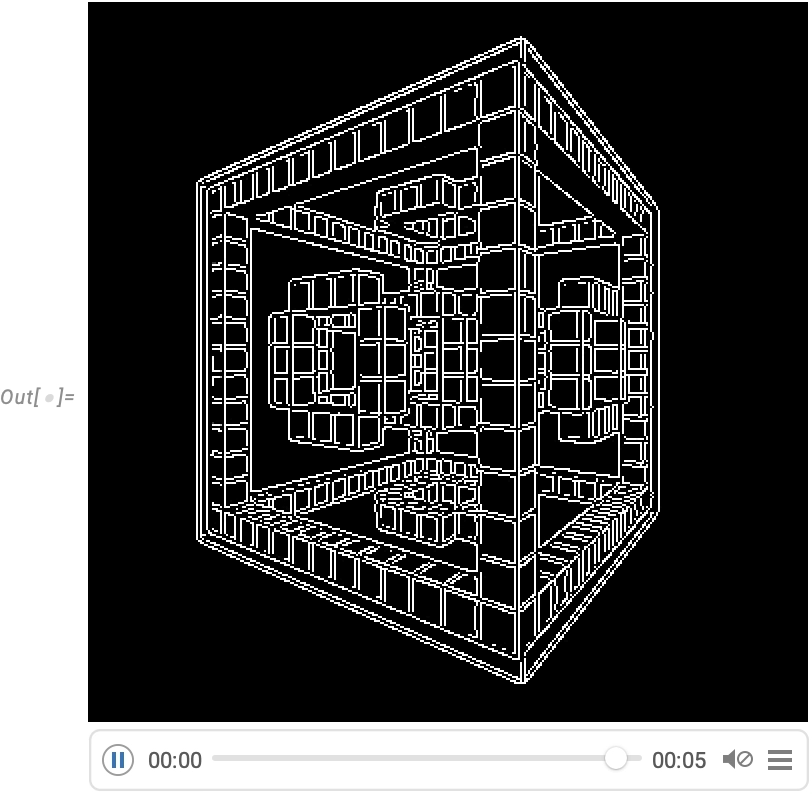
And though Wolfram Language isn’t meant as an interactive video modifying system, we’ve made positive that it’s doable to do streamlined programmatic video modifying within the language, and for instance in Model 14.0 we’ve added issues like transition results in VideoJoin and timed overlays in OverlayVideo.
So A lot Obtained Sooner, Stronger, Sleeker
With each new model of Wolfram Language we add new capabilities to increase but additional the area of the language. However we additionally put numerous effort into one thing much less instantly seen: making current capabilities quicker, stronger and sleeker.
And in Model 14 two areas the place we are able to see some examples of all these are dates and portions. We launched the notion of symbolic dates (DateObject, and so on.) almost a decade in the past. And over time since then we’ve constructed many issues on this construction. And within the technique of doing this it’s turn into clear that there are specific flows and paths which are significantly frequent and handy. Firstly what mattered most was simply to make it possible for the related performance existed. However over time we’ve been in a position to see what ought to be streamlined and optimized, and we’ve steadily been doing that.
As well as, as we’ve labored in direction of new and totally different functions, we’ve seen “corners” that should be stuffed in. So, for instance, astronomy is an space we’ve considerably developed in Model 14, and supporting astronomy has required including a number of new “high-precision” time capabilities, such because the TimeSystem possibility, in addition to new astronomy-oriented calendar programs. One other instance issues date arithmetic. What ought to occur if you wish to add a month to January 30? The place do you have to land? Completely different sorts of enterprise functions and contracts make totally different assumptions—and so we added a Methodology choice to features like DatePlus to deal with this. In the meantime, having realized that date arithmetic is concerned within the “inside loop” of sure computations, we optimized it—attaining a greater than 100x speedup in Model 14.0.
Wolfram|Alpha has been in a position to take care of items ever because it was first launched in 2009—now greater than 10,000 of them. And in 2012 we launched Amount to signify portions with items within the Wolfram Language. And over the previous decade we’ve been steadily smoothing out a complete collection of difficult gotchas and points with items. For instance, what does ![]() .
.
At first our precedence with Amount was to get it working as broadly as doable, and to combine it as broadly as doable into computations, visualizations, and so on. throughout the system. However as its capabilities have expanded, so have its makes use of, repeatedly driving the necessity to optimize its operation for explicit frequent instances. And certainly between Model 13 and Model 14 we’ve dramatically sped up many issues associated to Amount, typically by components of 1000 or extra.
Speaking of speedups, one other instance—made doable by new algorithms working on multithreaded CPUs—issues polynomials. We’ve labored with polynomials in Wolfram Language since Model 1, however in Model 13.2 there was a dramatic speedup of as much as 1000x on operations like polynomial factoring.
As well as, a brand new algorithm in Model 14.0 dramatically quickens numerical options to polynomial and transcendental equations—and, along with the brand new MaxRoots choices, permits us, for instance, to choose off a number of roots from a degree-one-million polynomial
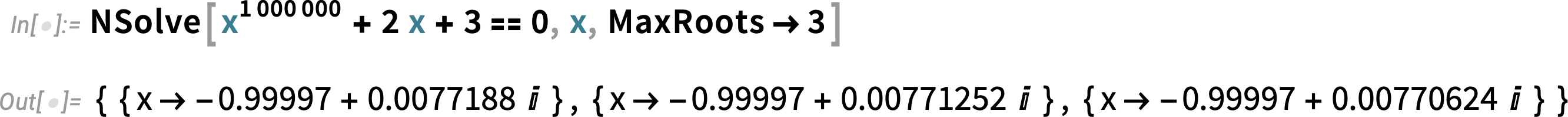
or to search out roots of a transcendental equation that we couldn’t even try earlier than with out pre-specifying bounds on their values:

One other “previous” piece of performance with current enhancement issues mathematical features. Ever since Model 1.0 we’ve arrange mathematical features in order that they are often computed to arbitrary precision:
However in current variations we’ve wished to be “extra exact about precision”, and to have the ability to rigorously compute simply what vary of outputs are doable given the vary of values supplied as enter:
However each operate for which we do that successfully requires a brand new theorem, and we’ve been steadily growing the variety of features lined—now greater than 130—in order that this “simply works” when it’s worthwhile to use it in a computation.
The Tree Story Continues
Timber are helpful. We first launched them as fundamental objects within the Wolfram Language solely in Model 12.3. However now that they’re there, we’re discovering an increasing number of locations they can be utilized. And to help that, we’ve been including an increasing number of capabilities to them.
One space that’s superior considerably since Model 13 is the rendering of timber. We tightened up the overall graphic design, however, extra importantly, we launched many new choices for the way rendering ought to be finished.
For instance, right here’s a random tree the place we’ve specified that for all nodes solely 3 kids ought to be explicitly displayed: the others are elided away:

Right here we’re including a number of choices to outline the rendering of the tree:

By default, the branches in timber are labeled with integers, similar to components in an expression. However in Model 13.1 we added help for named branches outlined by associations:

Our unique conception of timber was very centered round having components one would explicitly deal with, and that might have “payloads” connected. However what turned clear is that there have been functions the place all that mattered was the construction of the tree, not something about its components. So we added UnlabeledTree to create “pure timber”:

Timber are helpful as a result of many sorts of buildings are mainly timber. And since Model 13 we’ve added capabilities for changing timber to and from varied sorts of buildings. For instance, right here’s a easy Dataset object:

You should utilize ExpressionTree to transform this to a tree:

And TreeExpression to transform it again:

We’ve additionally added capabilities for changing to and from JSON and XML, in addition to for representing file listing buildings as timber:

Finite Fields
In Model 1.0 we had integers, rational numbers and actual numbers. In Model 3.0 we added algebraic numbers (represented implicitly by Root)—and a dozen years later we added algebraic quantity fields and transcendental roots. For Model 14 we’ve now added one other (long-awaited) “number-related” assemble: finite fields.
Right here’s our symbolic illustration of the sphere of integers modulo 7:

And now right here’s a particular component of that area

which we are able to instantly compute with:

However what’s actually essential about what we’ve finished with finite fields is that we’ve totally built-in them into different features within the system. So, for instance, we are able to issue a polynomial whose coefficients are in a finite area:

We will additionally do issues like discover options to equations over finite fields. So right here, for instance, is some extent on a Fermat curve over the finite area GF(173):

And here’s a energy of a matrix with components over the identical finite area:

Going Off Planet: The Astro Story
A serious new functionality added since Model 13 is astro computation. It begins with with the ability to compute to excessive precision the positions of issues like planets. Even figuring out what one means by “place” is difficult, although—with numerous totally different coordinate programs to take care of. By default AstroPosition provides the place within the sky on the present time out of your Right here location:

However one can as a substitute ask a few totally different coordinate system, like world galactic coordinates:

And now right here’s a plot of the gap between Saturn and Jupiter over a 50-year interval:

In direct analogy to GeoGraphics, we’ve added AstroGraphics, right here exhibiting a patch of sky across the present place of Saturn:

And this now reveals the sequence of positions for Saturn over the course of a few years—sure, together with retrograde movement:

There are a lot of styling choices for AstroGraphics. Right here we’re including a background of the “galactic sky”:

And right here we’re together with renderings for constellations (and, sure, we had an artist draw them):

One thing particularly new in Model 14.0 has to do with prolonged dealing with of photo voltaic eclipses. We at all times attempt to ship new performance as quick as we are able to. However on this case there was a really particular deadline: the full photo voltaic eclipse seen from the US on April 8, 2024. We’ve had the flexibility to do world computations about photo voltaic eclipses for a while (truly since quickly earlier than the 2017 eclipse). However now we are able to additionally do detailed native computations proper within the Wolfram Language.
So, for instance, right here’s a considerably detailed total map of the April 8, 2024 eclipse:

Now right here’s a plot of the magnitude of the eclipse over a number of hours, full with somewhat “rampart” related to the interval of totality:

And right here’s a map of the area of totality each minute simply after the second of most eclipse:

Thousands and thousands of Species Change into Computable
We first launched computable information on organic organisms again when Wolfram|Alpha was launched in 2009. However in Model 14—following a number of years of labor—we’ve dramatically broadened and deepened the computable information we’ve got about organic organisms.
So for instance right here’s how we are able to work out what species have cheetahs as predators:

And listed here are footage of those:

Right here’s a map of nations the place cheetahs have been seen (within the wild):

We now have information—curated from an ideal many sources—on greater than 1,000,000 species of animals, in addition to a lot of the crops, fungi, micro organism, viruses and archaea which have been described. And for animals, for instance, we’ve got almost 200 properties which are extensively stuffed in. Some are taxonomic properties:

Some are bodily properties:


Some are genetic properties:

Some are ecological properties (sure, the cheetah will not be the apex predator):

It’s helpful to have the ability to get properties of particular person species, however the actual energy of our curated computable information reveals up when one does larger-scale analyses. Like right here’s a plot of the lengths of genomes for organisms with the longest ones throughout our assortment of organisms:

Or right here’s a histogram of the genome lengths for organisms within the human intestine microbiome:

And right here’s a scatterplot of the lifespans of birds in opposition to their weights:

Following the concept that cheetahs aren’t apex predators, this can be a graph of what’s “above” them within the meals chain:

Chemical Computation
We started the method of introducing chemical computation into the Wolfram Language in Model 12.0, and by Model 13 we had good protection of atoms, molecules, bonds and purposeful teams. Now in Model 14 we’ve added protection of chemical formulation, quantities of chemical compounds—and chemical reactions.
Right here’s a chemical formulation, that mainly simply provides a “depend of atoms”:

Now listed here are particular molecules with that formulation:

Let’s decide certainly one of these molecules:

Now in Model 14 we’ve got a method to signify a sure amount of molecules of a given kind—right here 1 gram of methylcyclopentane:

ChemicalConvert can convert to a distinct specification of amount, right here moles:

And right here a depend of molecules:

However now the larger story is that in Model 14 we are able to signify not simply particular person kinds of molecules, and portions of molecules, but in addition chemical reactions. Right here we give a “sloppy” unbalanced illustration of a response, and ReactionBalance provides us the balanced model:

And now we are able to extract the formulation for the reactants:

We will additionally give a chemical response by way of molecules:

However with our symbolic illustration of molecules and reactions, there’s now a giant factor we are able to do: signify lessons of reactions as “sample reactions”, and work with them utilizing the identical sorts of ideas as we use in working with patterns for normal expressions. So, for instance, right here’s a symbolic illustration of the hydrohalogenation response:

Now we are able to apply this sample response to explicit molecules:

Right here’s a extra elaborate instance, on this case entered utilizing a SMARTS string:

Right here we’re making use of the response simply as soon as:

And now we’re doing it repeatedly
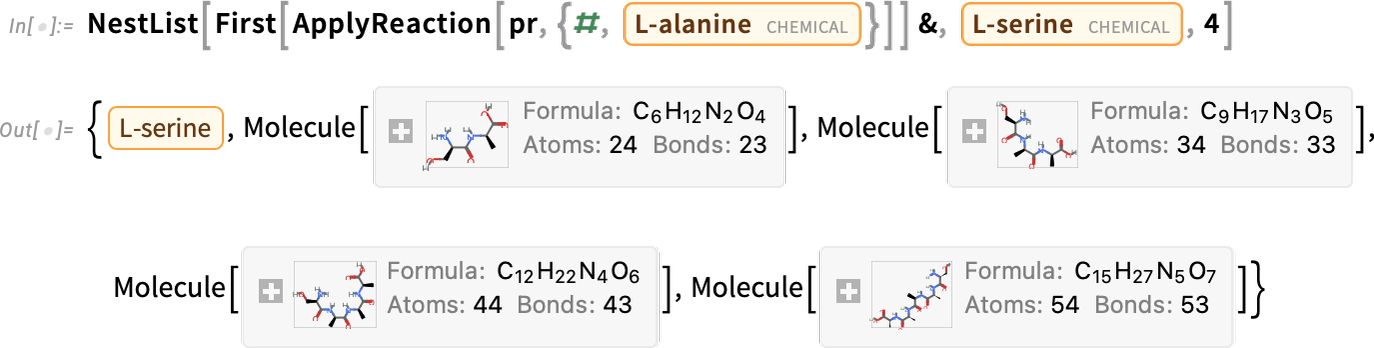
on this case producing longer and longer molecules (which on this case occur to be polypeptides):

The Knowledgebase Is At all times Rising
Each minute of every single day, new information is being added to the Wolfram Knowledgebase. A lot of it’s coming routinely from real-time feeds. However we even have a really large-scale ongoing curation effort with people within the loop. We’ve constructed subtle (Wolfram Language) automation for our information curation pipeline over time—and this 12 months we’ve been in a position to improve effectivity in some areas through the use of LLM expertise. But it surely’s laborious to do curation proper, and our long-term expertise is that to take action finally requires human specialists being within the loop, which we’ve got.
So what’s new since Model 13.0? 291,842 new notable present and historic folks; 264,467 music works; 118,538 music albums; 104,024 named stars; and so forth. Typically the addition of an entity is pushed by the brand new availability of dependable information; typically it’s pushed by the necessity to use that entity in another piece of performance (e.g. stars to render in AstroGraphics). However extra than simply including entities there’s the difficulty of filling in values of properties of current entities. And right here once more we’re at all times making progress, generally integrating newly out there large-scale secondary information sources, and generally doing direct curation ourselves from major sources.
A current instance the place we would have liked to do direct curation was in information on alcoholic drinks. Now we have very in depth information on a whole bunch of hundreds of kinds of meals and drinks. However none of our large-scale sources included information on alcoholic drinks. In order that’s an space the place we have to go to major sources (on this case sometimes the unique producers of merchandise) and curate the whole lot for ourselves.
So, for instance, we are able to now ask for one thing just like the distribution of flavors of various types of vodka (truly, personally, not being a client of such issues, I had no thought vodka even had flavors…):

However past filling out entities and properties of current varieties, we’ve additionally steadily been including new entity varieties. One current instance is geological formations, 13,706 of them:

So now, for instance, we are able to specify the place T. rex have been discovered

and we are able to present these areas on a map:
Industrial-Energy Multidomain PDEs
PDEs are laborious. It’s laborious to resolve them. And it’s laborious to even specify what precisely you need to clear up. However we’ve been on a multi-decade mission to “consumerize” PDEs and make them simpler to work with. Many issues go into this. You want to have the ability to simply specify elaborate geometries. You want to have the ability to simply outline mathematically difficult boundary circumstances. That you must have a streamlined method to arrange the difficult equations that come out of underlying physics. Then it’s important to—as routinely as doable—do the subtle numerical evaluation to effectively clear up the equations. However that’s not all. You additionally typically want to visualise your resolution, compute different issues from it, or run optimizations of parameters over it.
It’s a deep use of what we’ve constructed with Wolfram Language—touching many components of the system. And the result’s one thing distinctive: a very streamlined and built-in method to deal with PDEs. One’s not coping with some (often very costly) “only for PDEs” bundle; what we now have is a “consumerized” method to deal with PDEs every time they’re wanted—for engineering, science, or no matter. And, sure, with the ability to join machine studying, or picture computation, or curated information, or information science, or real-time sensor feeds, or parallel computing, or, for that matter, Wolfram Notebooks, to PDEs simply makes them a lot extra useful.
We’ve had “fundamental, uncooked NDSolve” since 1991. However what’s taken a long time to construct is all of the construction round that to let one conveniently arrange—and effectively clear up—real-world PDEs, and join them into the whole lot else. It’s taken creating a complete tower of underlying algorithmic capabilities equivalent to our more-flexible-and-integrated-than-ever-before industrial-strength computational geometry and finite component strategies. However past that it’s taken making a language for specifying real-world PDEs. And right here the symbolic nature of the Wolfram Language—and our complete design framework—has made doable one thing very distinctive, that has allowed us to dramatically simplify and consumerize the usage of PDEs.
It’s all about offering symbolic “development kits” for PDEs and their boundary circumstances. We began this about 5 years in the past, progressively protecting an increasing number of software areas. In Model 14 we’ve significantly centered on stable mechanics, fluid mechanics, electromagnetics and (one-particle) quantum mechanics.
Right here’s an instance from stable mechanics. First, we outline the variables we’re coping with (displacement and underlying coordinates):
Subsequent, we specify the parameters we need to use to explain the stable materials we’re going to work with:
Now we are able to truly arrange our PDE—utilizing symbolic PDE specs like SolidMechanicsPDEComponent—right here for the deformation of a stable object pulled on one facet:

And, sure, “beneath”, these easy symbolic specs flip into a sophisticated “uncooked” PDE:
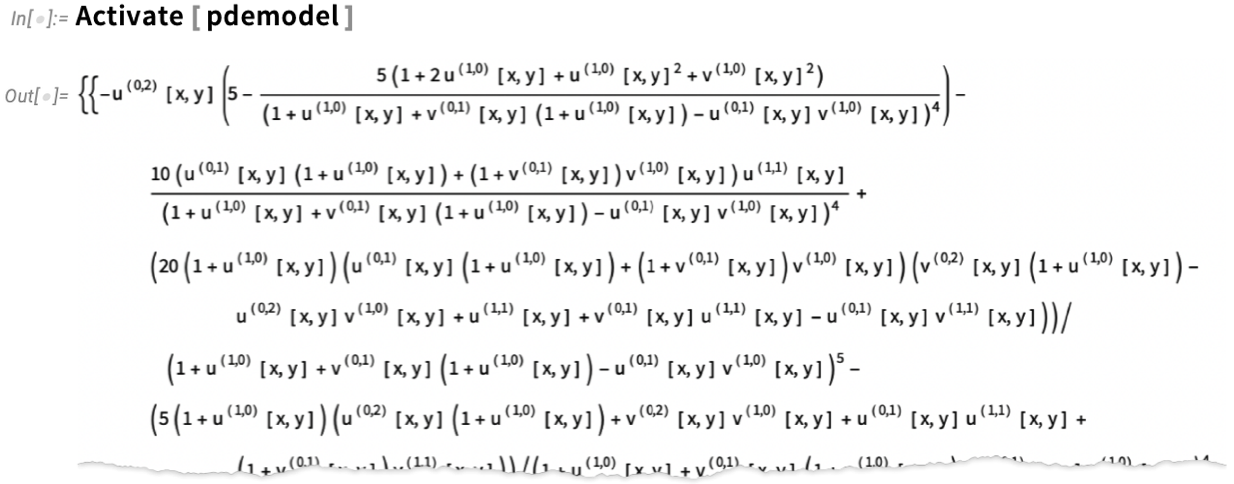
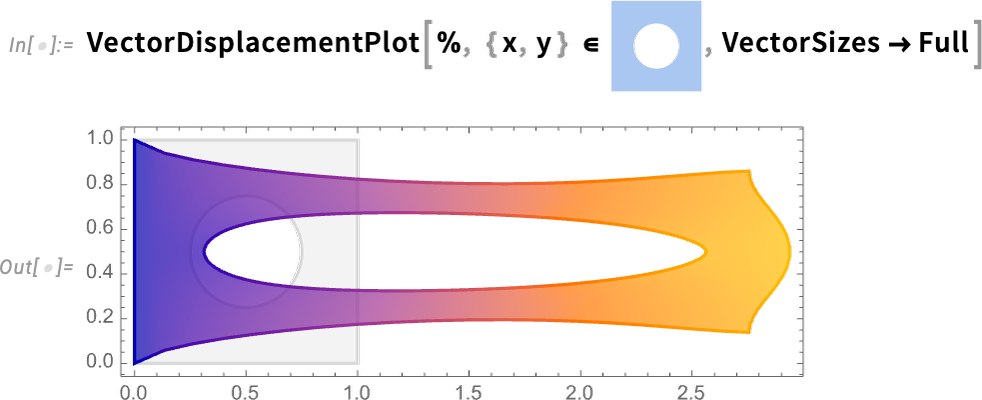
Now we’re prepared to really clear up our PDE in a specific area, i.e. for an object with a specific form:

And now we are able to visualize the end result, which reveals how our object stretches when it’s pulled on:
The way in which we’ve set issues up, the fabric for our object is an idealization of one thing like rubber. However within the Wolfram Language we now have methods to specify all kinds of detailed properties of supplies. So, for instance, we are able to add reinforcement as a unit vector in a specific course (say in follow with fibers) to our materials:
Then we are able to rerun what we did earlier than
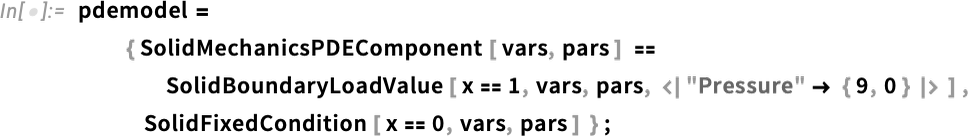
however now we get a barely totally different end result:
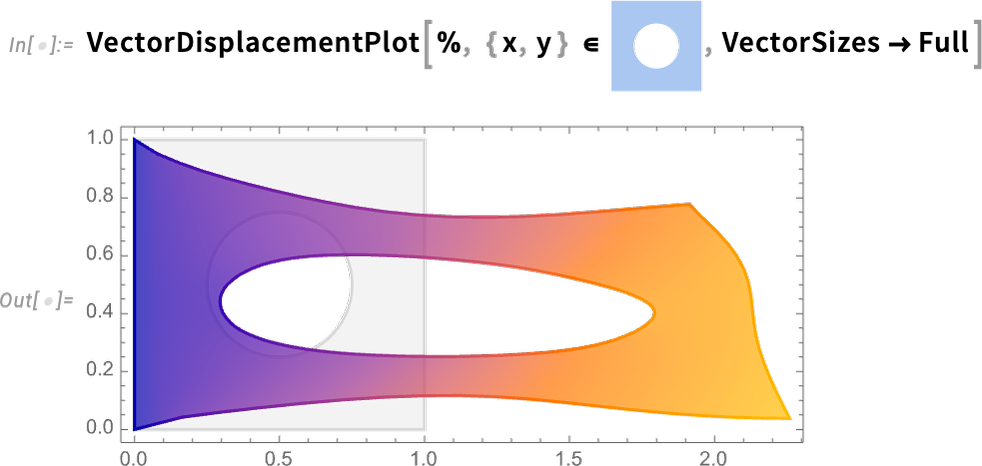
One other main PDE area that’s new in Model 14.0 is fluid circulate. Let’s do a 2D instance. Our variables are 2D velocity and strain:
Now we are able to arrange our fluid system in a specific area, with no-slip circumstances on all partitions besides on the high the place we assume fluid is flowing from left to proper. The one parameter wanted is the Reynolds quantity. And as a substitute of simply fixing our PDEs for a single Reynolds quantity, let’s create a parametric solver that may take any specified Reynolds quantity:

Now right here’s the end result for Reynolds quantity 100:
However with the best way we’ve set issues up, we are able to as nicely generate a complete video as a operate of Reynolds quantity (and, sure, the Parallelize speeds issues up by producing totally different frames in parallel):

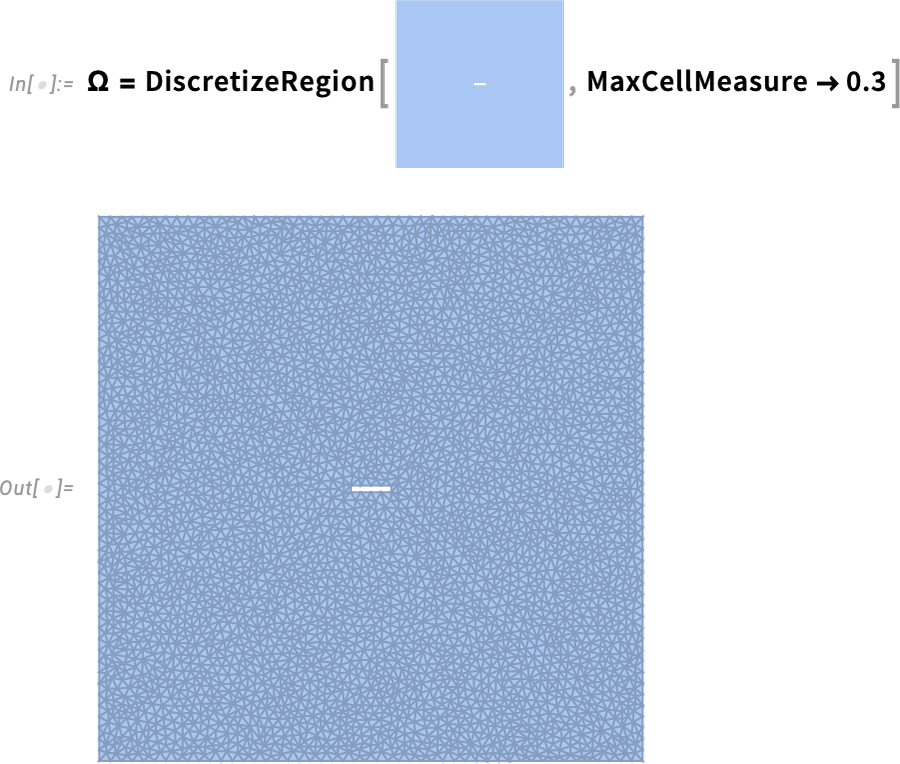
A lot of our work in PDEs entails catering to the complexities of real-world engineering conditions. However in Model 14.0 we’re additionally including options to help “pure physics”, and particularly to help quantum mechanics finished with the Schrödinger equation. So right here, for instance, is the 2D 1-particle Schrödinger equation (with ![]() ):
):

Right here’s the area we’re going to be fixing over—exhibiting express discretization:
Now we are able to clear up the equation, including in some boundary circumstances:
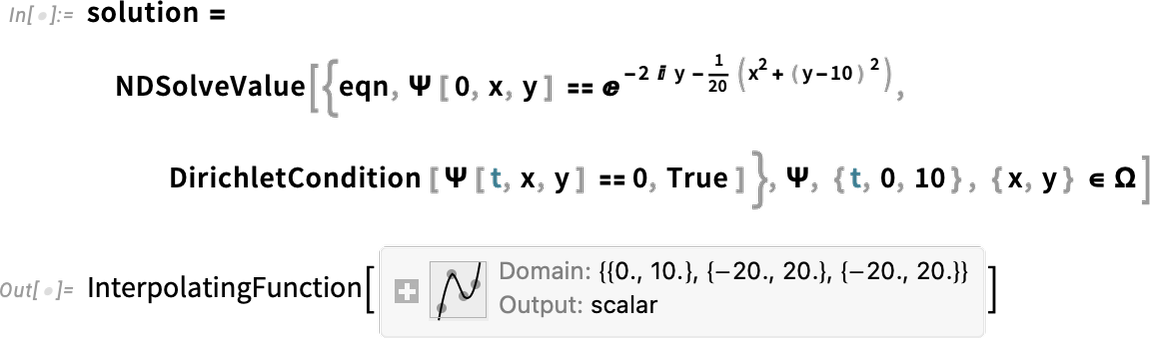
And now we get to visualise a Gaussian wave packet scattering round a barrier:
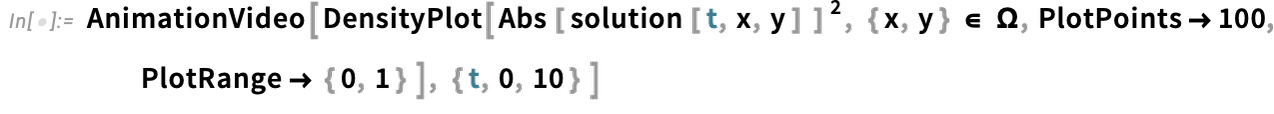
Streamlining Techniques Engineering Computation
Techniques engineering is a giant area, however it’s one the place the construction and capabilities of the Wolfram Language present distinctive benefits—that over the previous decade have allowed us to construct out slightly full industrial-strength help for modeling, evaluation and management design for a variety of kinds of programs. It’s all an built-in a part of the Wolfram Language, accessible by way of the computational and interface construction of the language. But it surely’s additionally built-in with our separate Wolfram System Modeler product, that gives a GUI-based workflow for system modeling and exploration.
Shared with System Modeler are massive collections of domain-specific modeling libraries. And, for instance, since Model 13, we’ve added libraries in areas equivalent to battery engineering, hydraulic engineering and plane engineering—in addition to academic libraries for mechanical engineering, thermal engineering, digital electronics, and biology. (We’ve additionally added libraries for areas equivalent to enterprise and public coverage simulation.)

A typical workflow for programs engineering begins with the establishing of a mannequin. The mannequin might be constructed from scratch, or assembled from elements in mannequin libraries—both visually in Wolfram System Modeler, or programmatically within the Wolfram Language. For instance, right here’s a mannequin of an electrical motor that’s turning a load by way of a versatile shaft:
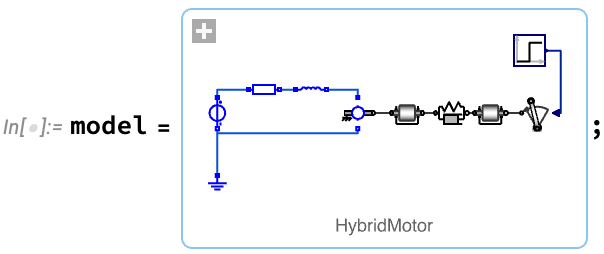
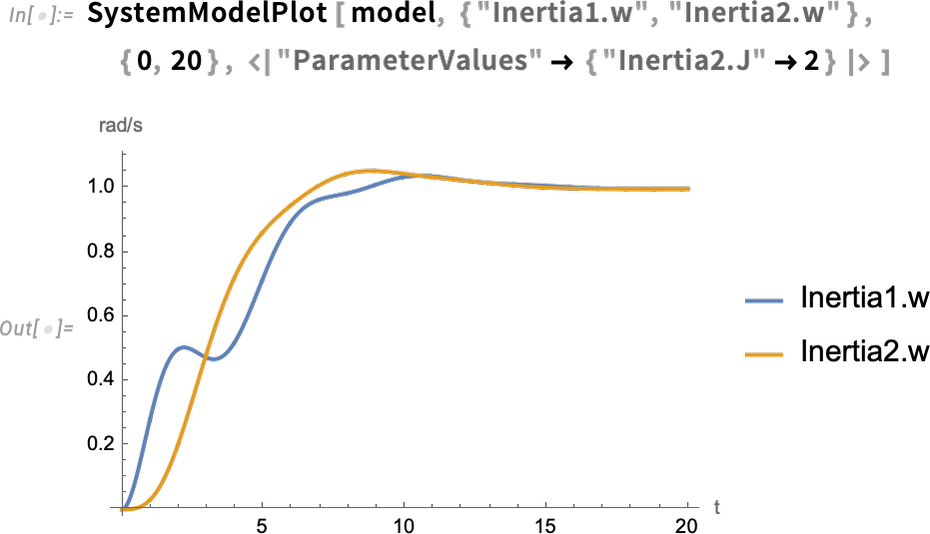
As soon as one’s acquired a mannequin, one can then simulate it. Right here’s an instance the place we’ve set one parameter of our mannequin (the second of inertia of the load), and we’re computing the values of two others as a operate of time:
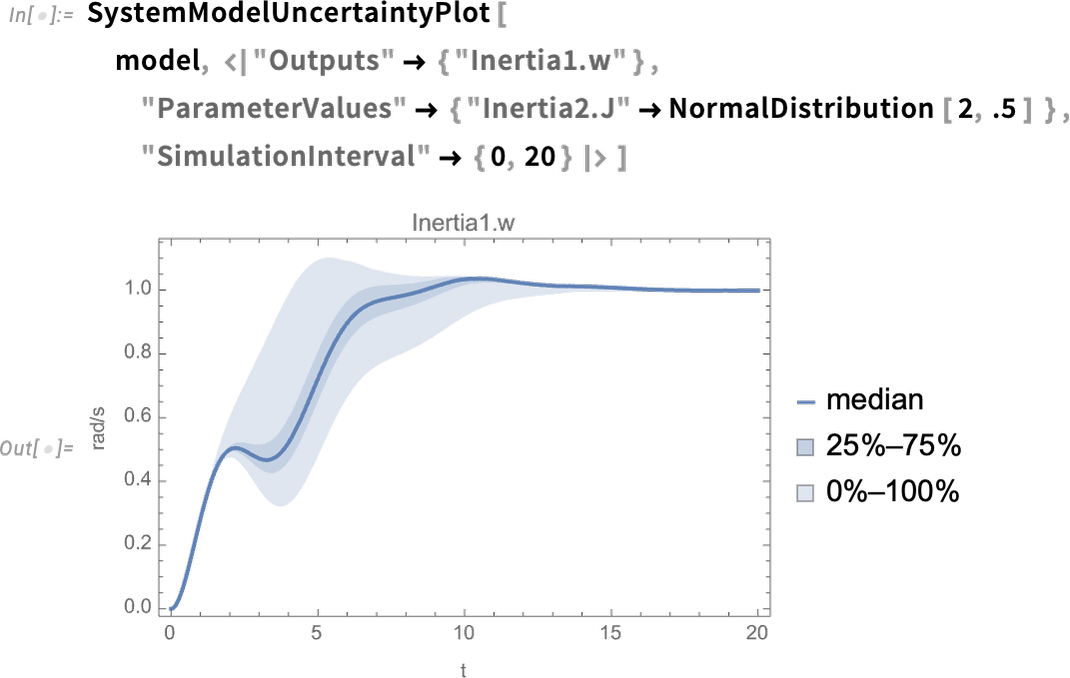
A brand new functionality in Model 14.0 is with the ability to see the impact of uncertainty in parameters (or preliminary values, and so on.) on the habits of a system. So right here, for example, we’re saying the worth of the parameter will not be particular, however is as a substitute distributed in accordance with a traditional distribution—then we’re seeing the distribution of output outcomes:
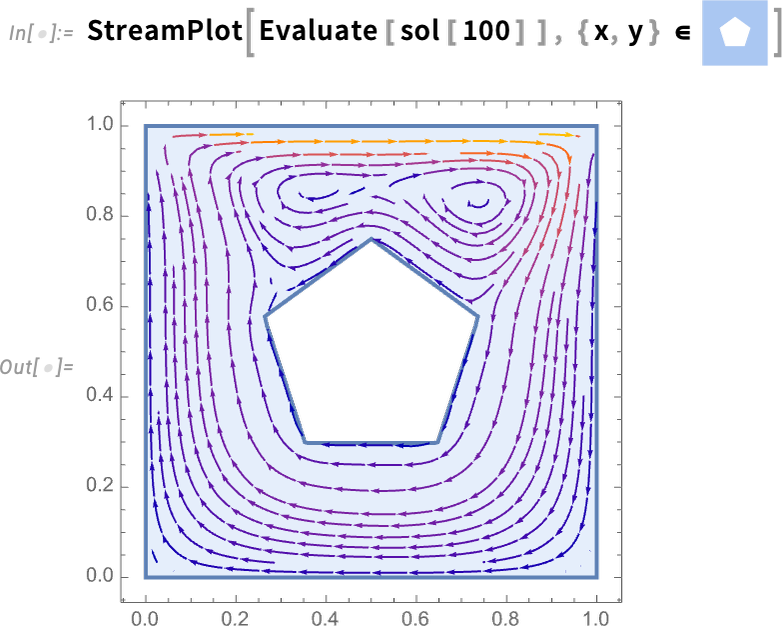
The motor with versatile shaft that we’re taking a look at might be regarded as a “multidomain system”, combining electrical and mechanical elements. However the Wolfram Language (and Wolfram System Modeler) may also deal with “combined programs”, combining analog and digital (i.e. steady and discrete) elements. Right here’s a reasonably subtle instance from the world of management programs: a helicopter mannequin linked in a closed loop to a digital management system:

This complete mannequin system might be represented symbolically simply by:
And now we compute the input-output response of the mannequin:

Right here’s particularly the output response:
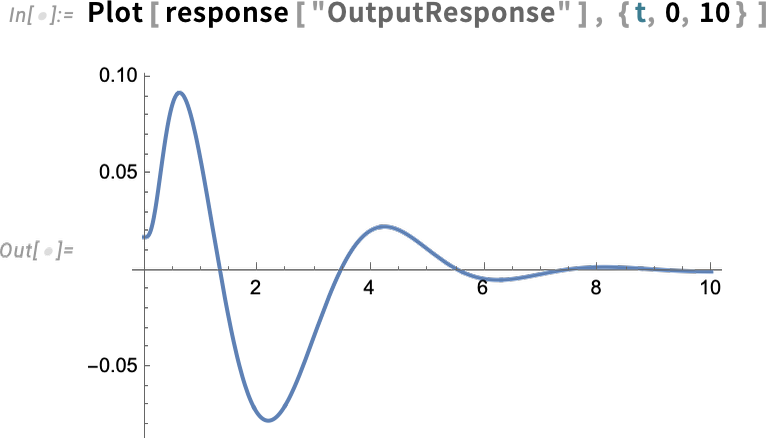
However now we are able to “drill in” and see particular subsystem responses, right here of the zero-order maintain machine (labeled ZOH above)—full with its little digital steps:
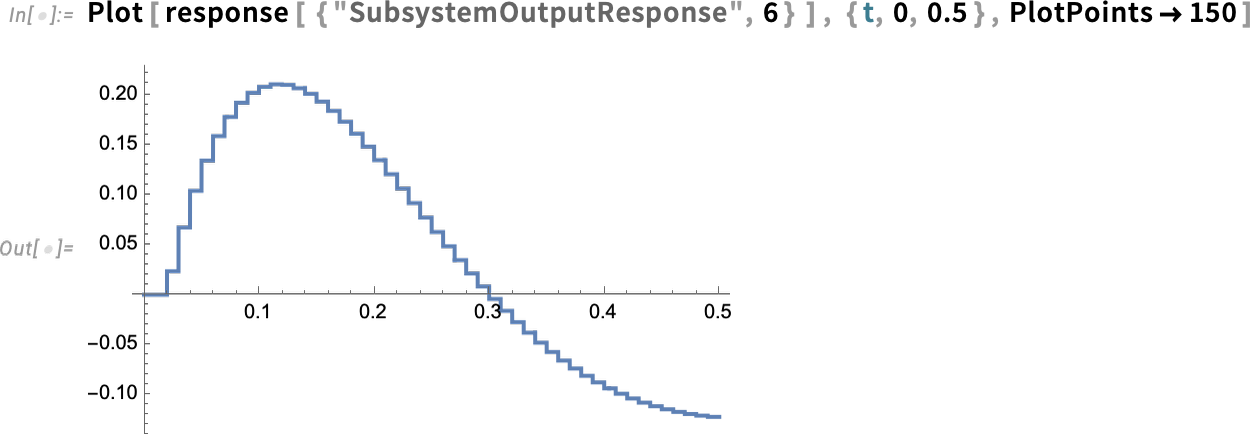
However what if we need to design the management programs ourselves? Effectively, in Model 14 we are able to now apply all our Wolfram Language management programs design performance to arbitrary system fashions. Right here’s an instance of a easy mannequin, on this case in chemical engineering (a constantly stirred tank):

Now we are able to take this mannequin and design an LQG controller for it—then assemble a complete closed-loop system for it:
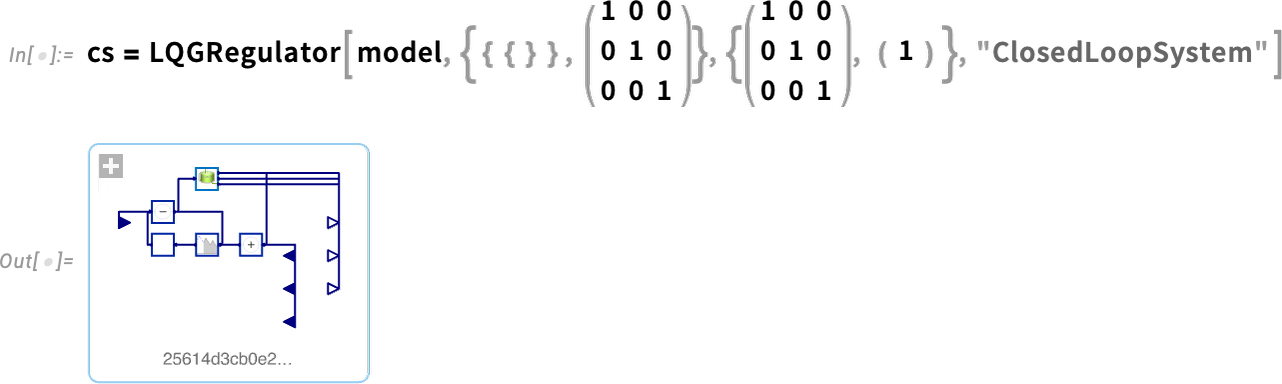
Now we are able to simulate the closed-loop system—and see that the controller succeeds in bringing the ultimate worth to 0:
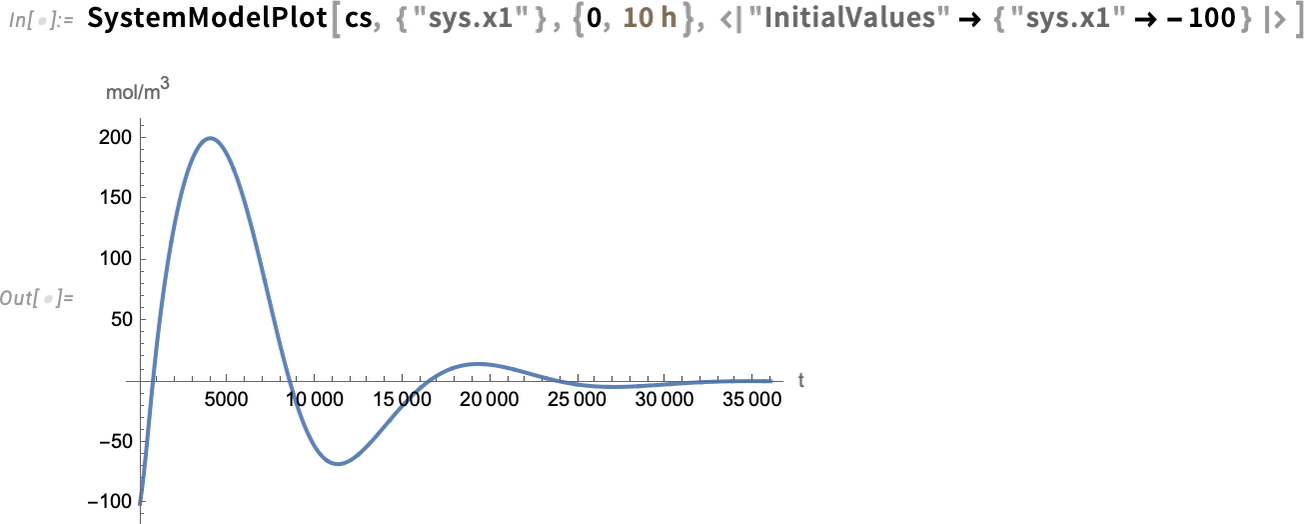
Graphics: Extra Lovely & Alive
Graphics have at all times been an essential a part of the story of the Wolfram Language, and for greater than three a long time we’ve been progressively enhancing and updating their look and performance—generally with assist from advances in {hardware} (e.g. GPU) capabilities.
Since Model 13 we’ve added a wide range of “ornamental” (or “annotative”) results in 2D graphics. One instance (helpful for placing captions on issues) is Haloing:

One other instance is DropShadowing:

All of those are specified symbolically, and can be utilized all through the system (e.g. in hover results, and so on). And, sure, there are various detailed parameters you possibly can set:
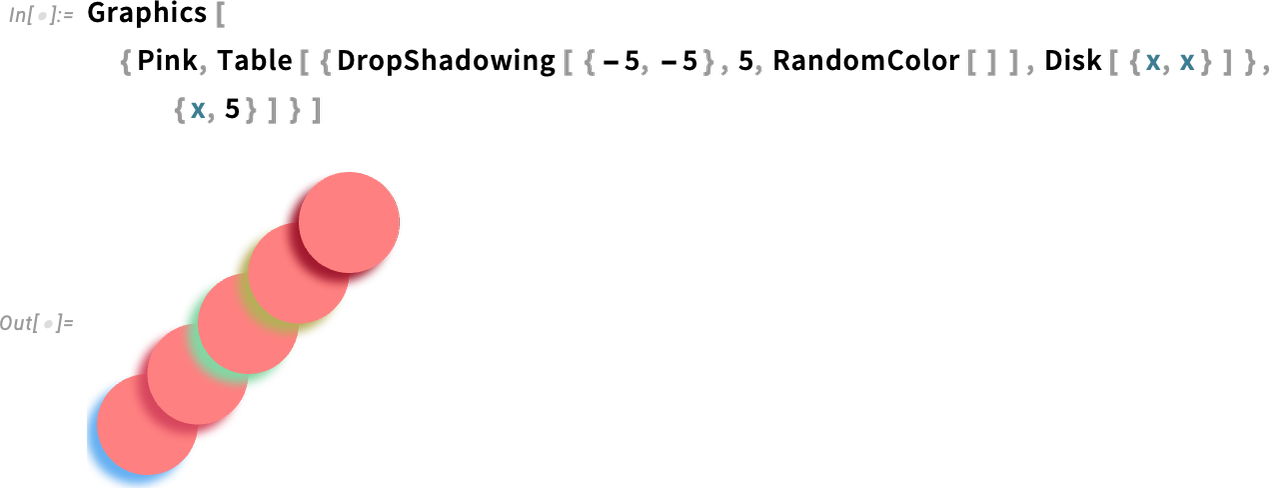
A major new functionality in Model 14.0 is handy texture mapping. We’ve had low-level polygon-by-polygon textures for a decade and a half. However now in Model 14.0 we’ve made it simple to map textures onto complete surfaces. Right here’s an instance wrapping a texture onto a sphere:

And right here’s wrapping the identical texture onto a extra difficult floor:

A major subtlety is that there are various methods to map what quantity to “texture coordinate patches” onto surfaces. The documentation illustrates new, named instances:

And now right here’s what occurs with stereographic projection onto a sphere:

Right here’s an instance of “floor texture” for the planet Venus

and right here it’s been mapped onto a sphere, which might be rotated:


Right here’s a “flowerified” bunny:

Issues like texture mapping assist make graphics visually compelling. Since Model 13 we’ve additionally added a wide range of “dwell visualization” capabilities that routinely “deliver visualizations to life”. For instance, any plot now by default has a “coordinate mouseover”:
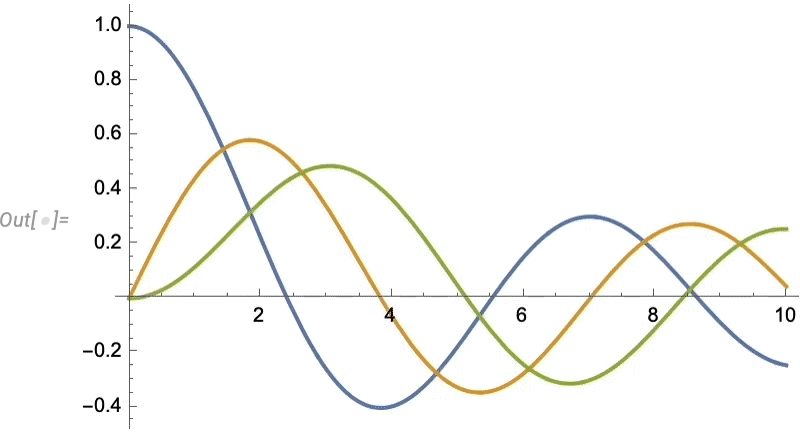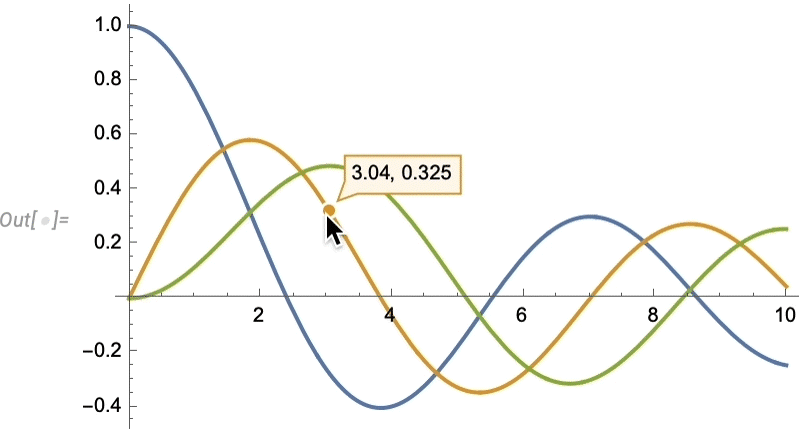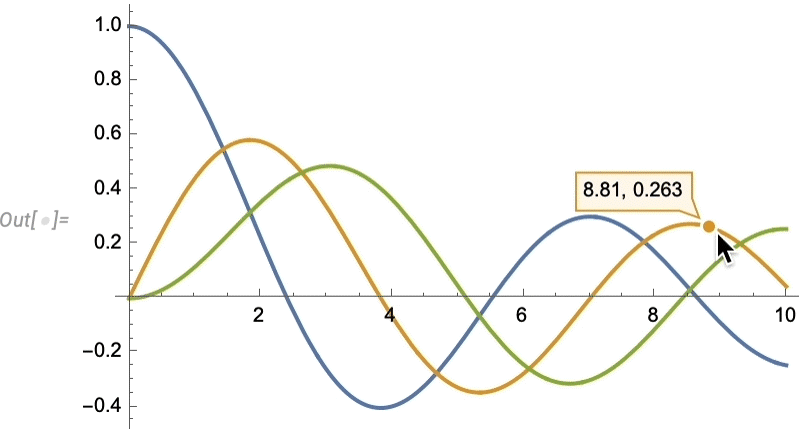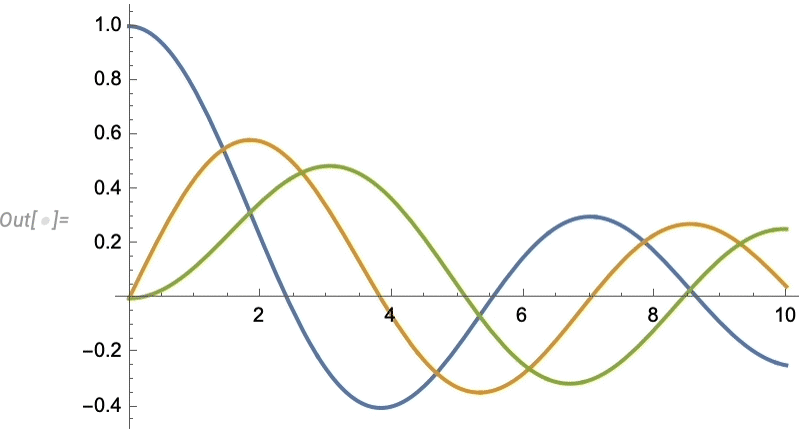
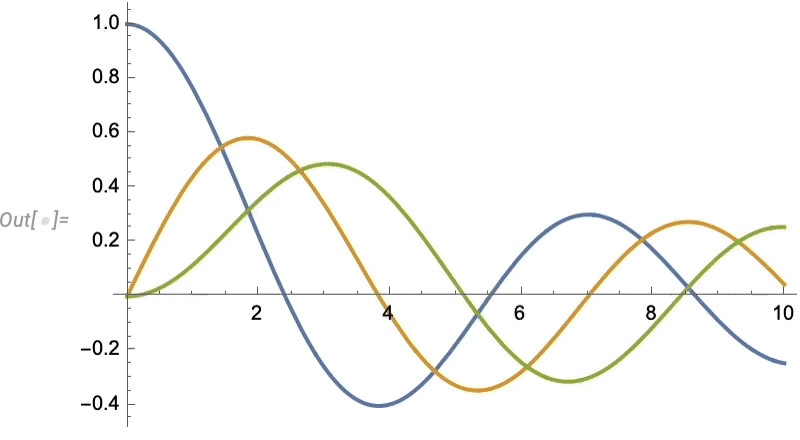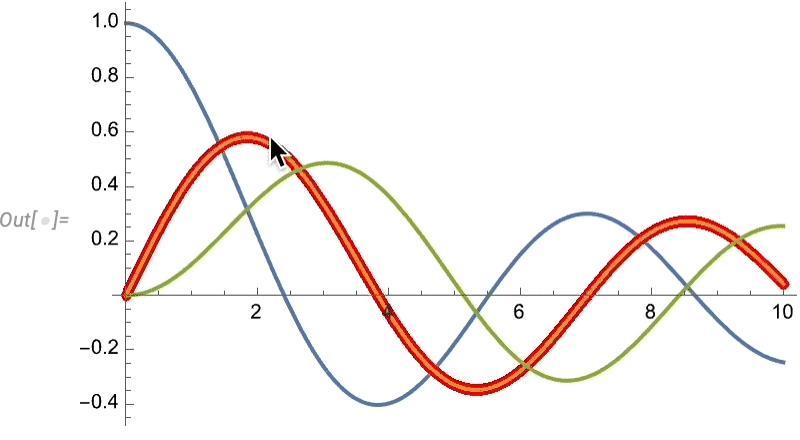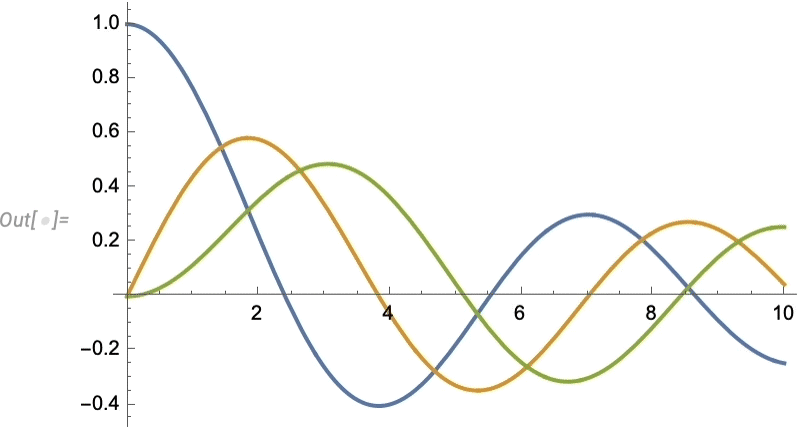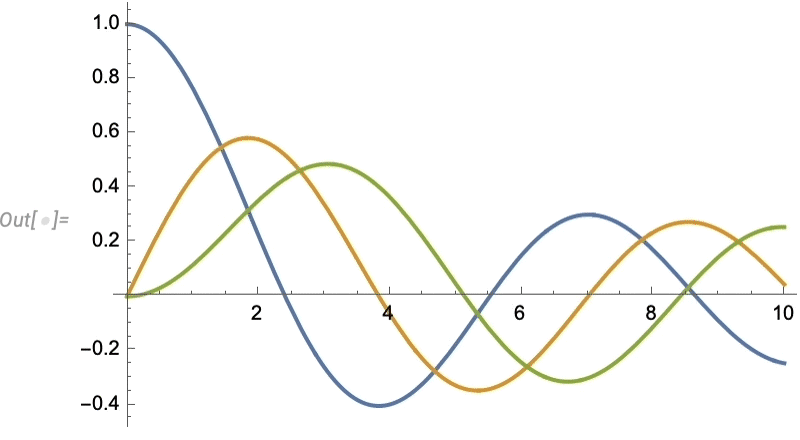
As standard, there’s numerous methods to regulate such “highlighting” results:


Euclid Redux: The Advance of Artificial Geometry
One may say it’s been two thousand years within the making. However 4 years in the past (Model 12) we started to introduce a computable model of Euclid-style artificial geometry.
The thought is to specify geometric scenes symbolically by giving a set of (doubtlessly implicit) constraints:

We will then generate a random occasion of geometry in step with the constraints—and in Model 14 we’ve significantly enhanced our potential to make it possible for geometry can be “typical” and non-degenerate:

However now a brand new characteristic of Model 14 is that we are able to discover values of geometric portions which are decided by the constraints:

Right here’s a barely extra difficult case:

And right here we’re now fixing for the areas of two triangles within the determine:

We’ve at all times been in a position to give express kinds for explicit components of a scene:
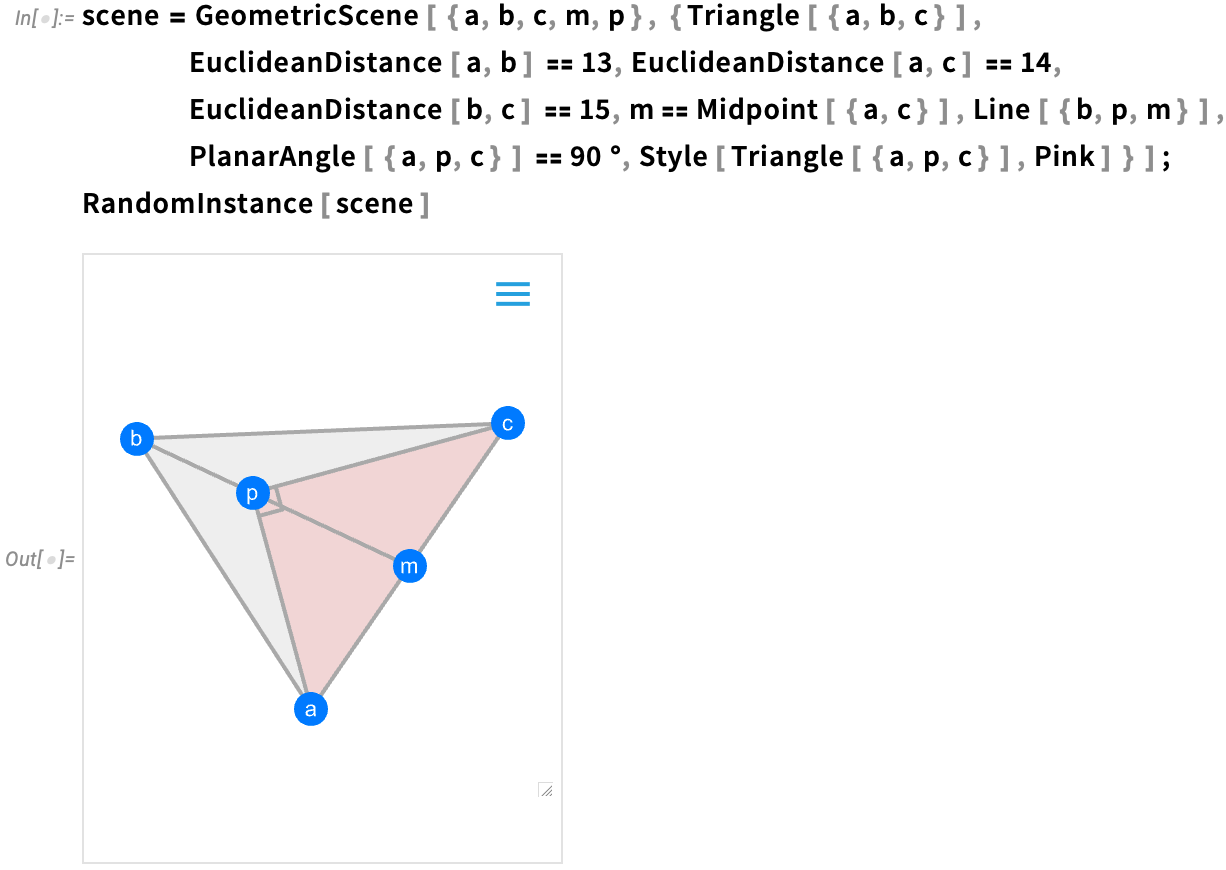
Now one of many new options in Model 14 is with the ability to give normal “geometric styling guidelines”, right here simply assigning random colours to every component:

The Ever-Smoother Person Interface
Our objective with Wolfram Language is to make it as straightforward as doable to specific oneself computationally. And a giant a part of attaining that’s the coherent design of the language itself. However there’s one other half as nicely, which is with the ability to truly enter Wolfram Language enter one desires—say in a pocket book—as simply as doable. And with each new model we make enhancements to this.
One space that’s been in steady improvement is interactive syntax highlighting. We first added syntax highlighting almost 20 years in the past—and over time we’ve progressively made it an increasing number of subtle, responding each as you kind, and as code will get executed. Some highlighting has at all times had apparent which means. However significantly highlighting that’s dynamic and based mostly on cursor place has generally been more durable to interpret. And in Model 14—leveraging the brighter coloration palettes which have turn into the norm in recent times—we’ve tuned our dynamic highlighting so it’s simpler to shortly inform “the place you might be” throughout the construction of an expression:

With reference to “figuring out what one has”, one other enhancement—added in Model 13.2—is differentiated body coloring for various sorts of visible objects in notebooks. Is that factor one has a graphic? Or a picture? Or a graph? Now one can inform from the colour of body when one selects it:

An essential facet of the Wolfram Language is that the names of built-in features are spelled out sufficient that it’s straightforward to inform what they do. However typically the names are subsequently essentially fairly lengthy, and so it’s essential to have the ability to autocomplete them when one’s typing. In 13.3 we added the notion of “fuzzy autocompletion” that not solely “completes to the tip” a reputation one’s typing, but in addition can fill in intermediate letters, change capitalization, and so on. Thus, for instance, simply typing lll brings up an autocompletion menu that begins with ListLogLogPlot:

A serious consumer interface replace that first appeared in Model 13.1—and has been enhanced in subsequent variations—is a default toolbar for each pocket book:
![]()
The toolbar offers quick entry to analysis controls, cell formatting and varied sorts of enter (like inline cells, ![]() , hyperlinks, drawing canvas, and so on.)—in addition to to issues like
, hyperlinks, drawing canvas, and so on.)—in addition to to issues like ![]() cloud publishing,
cloud publishing, ![]() documentation search and
documentation search and ![]() “chat” (i.e. LLM) settings.
“chat” (i.e. LLM) settings.
A lot of the time, it’s helpful to have the toolbar displayed in any pocket book you’re working with. However on the left-hand facet there’s somewhat tiny ![]() that permits you to decrease the toolbar:
that permits you to decrease the toolbar:

In 14.0 there’s a Preferences setting that makes the toolbar come up minimized in any new pocket book you create—and this in impact provides you the perfect of each worlds: you have got quick entry to the toolbar, however your notebooks don’t have something “additional” which may distract from their content material.
One other factor that’s superior since Model 13 is the dealing with of “abstract” types of output in notebooks. A fundamental instance is what occurs in case you generate a really massive end result. By default solely a abstract of the end result is definitely displayed. However now there’s a bar on the backside that offers varied choices for the right way to deal with the precise output:

By default, the output is barely saved in your present kernel session. However by urgent the Iconize button you get an iconized kind that can seem immediately in your pocket book (or one that may be copied wherever) and that “has the entire output inside”. There’s additionally a Retailer full expression in pocket book button, which is able to “invisibly” retailer the output expression “behind” the abstract show.
If the expression is saved within the pocket book, then it’ll be persistent throughout kernel periods. In any other case, nicely, you gained’t be capable to get to it in a distinct kernel session; the one factor you’ll have is the abstract show:

It’s the same story for big “computational objects”. Like right here’s a Nearest operate with 1,000,000 information factors:
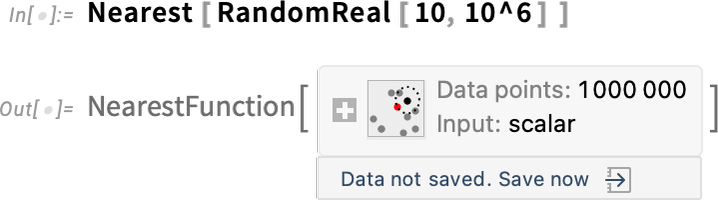
By default, the information is simply one thing that exists in your present kernel session. However now there’s a menu that permits you to save the information in varied persistent areas:

And There’s the Cloud Too
There are a lot of methods to run the Wolfram Language. Even in Model 1.0 we had the notion of distant kernels: the pocket book entrance finish operating on one machine (in these days basically at all times a Mac, or a NeXT), and the kernel operating on a distinct machine (in these days generally even linked by telephone traces). However a decade in the past got here a serious step ahead: the Wolfram Cloud.
There are actually two distinct methods wherein the cloud is used. The primary is in delivering a pocket book expertise much like our longtime desktop expertise, however operating purely in a browser. And the second is in delivering APIs and different programmatically accessed capabilities—notably, even in the beginning, a decade in the past, by way of issues like APIFunction.
The Wolfram Cloud has been the goal of intense improvement now for almost 15 years. Alongside it have additionally come Wolfram Utility Server and Wolfram Internet Engine, which offer extra streamlined help particularly for APIs (with out issues like consumer administration, and so on., however with issues like clustering).
All of those—however significantly the Wolfram Cloud—have turn into core expertise capabilities for us, supporting a lot of our different actions. So, for instance, the Wolfram Operate Repository and Wolfram Paclet Repository are each based mostly on the Wolfram Cloud (and in reality that is true of our complete useful resource system). And after we got here to construct the Wolfram plugin for ChatGPT earlier this 12 months, utilizing the Wolfram Cloud allowed us to have the plugin deployed inside a matter of days.
Since Model 13 there have been fairly a number of very totally different functions of the Wolfram Cloud. One is for the operate ARPublish, which takes 3D geometry and places it within the Wolfram Cloud with acceptable metadata to permit telephones to get augmented-reality variations from a QR code of a cloud URL:


On the Cloud Pocket book facet, there’s been a gentle improve in utilization, notably of embedded Cloud Notebooks, which have for instance turn into frequent on Wolfram Neighborhood, and are used all around the Wolfram Demonstrations Undertaking. Our objective all alongside has been to make Cloud Notebooks be as straightforward to make use of as easy webpages, however to have the depth of capabilities that we’ve developed in notebooks over the previous 35 years. We achieved this some years in the past for pretty small notebooks, however prior to now couple of years we’ve been going progressively additional in dealing with even multi-hundred-megabyte notebooks. It’s a sophisticated story of caching, refreshing—and dodging the vicissitudes of internet browsers. However at this level the overwhelming majority of notebooks might be seamlessly deployed to the cloud, and can show as instantly as easy webpages.
The Nice Integration Story for Exterior Code
It’s been doable to name exterior code from Wolfram Language ever since Model 1.0. However in Model 14 there are essential advances within the extent and ease with which exterior code might be built-in. The general objective is to have the ability to use all the ability and coherence of the Wolfram Language even when some a part of a computation is completed in exterior code. And in Model 14 we’ve finished loads to streamline and automate the method by which exterior code might be built-in into the language.
As soon as one thing is built-in into the Wolfram Language it simply turns into, for instance, a operate that can be utilized similar to another Wolfram Language operate. However what’s beneath is essentially fairly totally different for various sorts of exterior code. There’s one setup for interpreted languages like Python. There’s one other for C-like compiled languages and dynamic libraries. (After which there are others for exterior processes, APIs, and what quantity to “importable code specs”, say for neural networks.)
Let’s begin with Python. We’ve had ExternalEvaluate for evaluating Python code since 2018. However whenever you truly come to make use of Python there are all these dependencies and libraries to take care of. And, sure, that’s one of many locations the place the unimaginable benefits of the Wolfram Language and its coherent design are painfully evident. However in Model 14.0 we now have a method to encapsulate all that Python complexity, in order that we are able to ship Python performance inside Wolfram Language, hiding all of the messiness of Python dependencies, and even the versioning of Python itself.
For example, let’s say we need to make a Wolfram Language operate Emojize that makes use of the Python operate emojize throughout the emoji Python library. Right here’s how we are able to try this:

And now you possibly can simply name Emojize within the Wolfram Language and—underneath the hood—it’ll run Python code:

The way in which this works is that the primary time you name Emojize, a Python setting with all the fitting options is created, then is cached for subsequent makes use of. And what’s essential is that the Wolfram Language specification of Emojize is totally system impartial (or as system impartial as it may be, given vicissitudes of Python implementations). So meaning you could, for instance, deploy Emojize within the Wolfram Operate Repository similar to you’d deploy one thing written purely in Wolfram Language.
There’s very totally different engineering concerned in calling C-compatible features in dynamic libraries. However in Model 13.3 we additionally made this very streamlined utilizing the operate ForeignFunctionLoad. There’s all kinds of complexity related to changing to and from native C information varieties, managing reminiscence for information buildings, and so on. However we’ve now acquired very clear methods to do that in Wolfram Language.
For example, right here’s how one units up a “international operate” name to a operate RAND_bytes within the OpenSSL library:
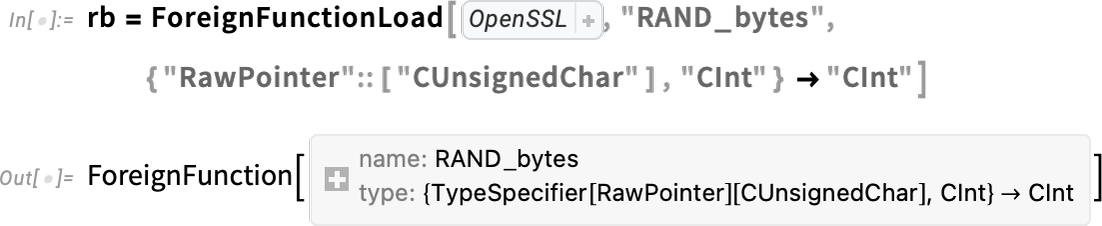
Inside this, we’re utilizing Wolfram Language compiler expertise to specify the native C varieties that can be used within the international operate. However now we are able to bundle this all up right into a Wolfram Language operate:

And we are able to name this operate similar to another Wolfram Language operate:
Internally, all kinds of difficult issues are happening. For instance, we’re allocating a uncooked reminiscence buffer that’s then getting fed to our C operate. However after we try this reminiscence allocation we’re making a symbolic construction that defines it as a “managed object”:
And now when this object is now not getting used, the reminiscence related to it is going to be routinely freed.
And, sure, with each Python and C there’s fairly a little bit of complexity beneath. However the excellent news is that in Model 14 we’ve mainly been in a position to automate dealing with it. And the result’s that what will get uncovered is pure, easy Wolfram Language.
However there’s one other huge piece to this. Inside explicit Python or C libraries there are sometimes elaborate definitions of knowledge buildings which are particular to that library. And so to make use of these libraries one has to dive into all of the—doubtlessly idiosyncratic—complexities of these definitions. However within the Wolfram Language we’ve got constant symbolic representations for issues, whether or not they’re photos, or dates or kinds of chemical compounds. Once you first hook up an exterior library it’s important to map its information buildings to those. However as soon as that’s finished, anybody can use what’s been constructed, and seamlessly combine with different issues they’re doing, maybe even calling different exterior code. In impact what’s occurring is that one’s leveraging the entire design framework of the Wolfram Language, and making use of that even when one’s utilizing underlying implementations that aren’t based mostly on the Wolfram Language.
For Severe Builders
A single line (or much less) of Wolfram Language code can do loads. However one of many exceptional issues in regards to the language is that it’s essentially scalable: good each for very brief applications and really lengthy applications. And since Model 13 there’ve been a number of advances in dealing with very lengthy applications. One in every of them issues “code modifying”.
Commonplace Wolfram Notebooks work very nicely for exploratory, expository and lots of different types of work. And it’s actually doable to put in writing massive quantities of code in commonplace notebooks (and, for instance, I personally do it). However when one’s doing “software-engineering-style work” it’s each extra handy and extra acquainted to make use of what quantities to a pure code editor, largely separate from code execution and exposition. And because of this we’ve got the “bundle editor”, accessible from File > New > Package deal/Script. You’re nonetheless working within the pocket book setting, with all its subtle capabilities. However issues have been “skinned” to supply a way more textual “code expertise”—each by way of modifying, and by way of what truly will get saved in .wl information.
Right here’s typical instance of the bundle editor in motion (on this case utilized to our GitLink bundle):

A number of issues are instantly evident. First, it’s very line oriented. Traces (of code) are numbered, and don’t break besides at express newlines. There are headings similar to in extraordinary notebooks, however when the file is saved, they’re saved as feedback with a sure stylized construction:

It’s nonetheless completely doable to run code within the bundle editor, however the output gained’t get saved within the .wl file:

One factor that’s modified since Model 13 is that the toolbar is way enhanced. And for instance there’s now “good search” that’s conscious of code construction:

You may also ask to go to a line quantity—and also you’ll instantly see no matter traces of code are close by:

Along with code modifying, one other set of options new since Model 13 of significance to severe builders concern automated testing. The primary advance is the introduction of a completely symbolic testing framework, wherein particular person checks are represented as symbolic objects
and might be manipulated in symbolic kind, then run utilizing features like TestEvaluate and TestReport:

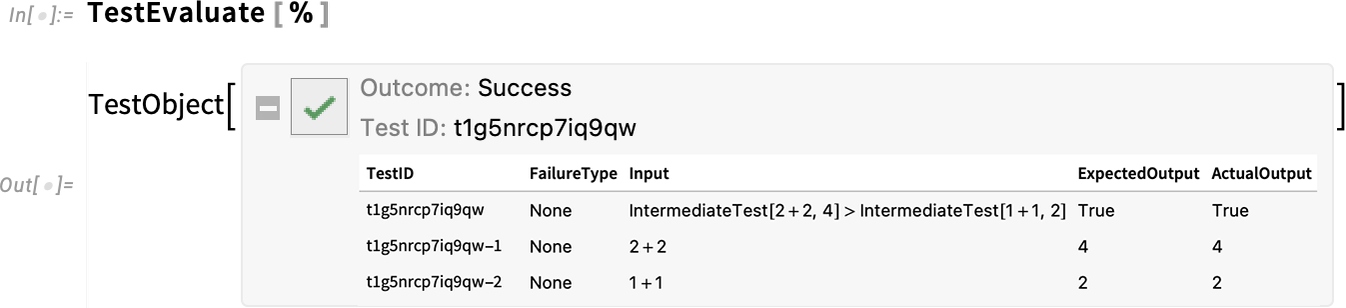
In Model 14.0 there’s one other new testing operate—IntermediateTest—that permits you to insert what quantity to checkpoints inside bigger checks:

Evaluating this check, we see that the intermediate checks had been additionally run:
Wolfram Operate Repository: 2900 Features & Counting
The Wolfram Operate Repository has been a giant success. We launched it in 2019 as a method to make particular, particular person contributed features out there within the Wolfram Language. And now there are greater than 2900 such features within the Repository.
The almost 7000 features that represent the Wolfram Language as it’s right now have been painstakingly developed over the previous three and a half a long time, at all times conscious of making a coherent complete with constant design ideas. And now in a way the success of the Operate Repository is likely one of the dividends of all that effort. As a result of it’s the coherence and consistency of the underlying language and its design ideas that make it possible to only add one operate at a time, and have it actually work. You need to add a operate to do some very particular operation that mixes photos and graphs. Effectively, there’s a constant illustration of each photos and graphs within the Wolfram Language, which you’ll be able to leverage. And by following the ideas of the Wolfram Language—like for the naming of features—you possibly can create a operate that’ll be straightforward for Wolfram Language customers to know and use.
Utilizing the Wolfram Operate Repository is a remarkably seamless course of. If you realize the operate’s title, you possibly can simply name it utilizing ResourceFunction; the operate can be loaded if it’s wanted, after which it’ll simply run:

If there’s an replace out there for the operate, it’ll provide you with a message, however run the previous model anyway. The message has a button that permits you to load within the replace; then you possibly can rerun your enter and use the brand new model. (For those who’re writing code the place you need to “burn in” a specific model of a operate, you possibly can simply use the ResourceVersion possibility of ResourceFunction.)
If you’d like your code to look extra elegant, simply consider the ResourceFunction object

and use the formatted model:

And, by the best way, urgent the + then provides you extra details about the operate:

An essential characteristic of features within the Operate Repository is that all of them have documentation pages—which are organized just about just like the pages for built-in features:

However how does one create a Operate Repository entry? Simply go to File > New > Repository Merchandise > Operate Repository Merchandise and also you’ll get a Definition Pocket book:

We’ve optimized this to be as straightforward to fill in as doable, minimizing boilerplate and routinely checking for correctness and consistency every time doable. And the result’s that it’s completely life like to create a easy Operate Repository merchandise in underneath an hour—with the primary time spent being within the writing of fine expository examples.
Once you press Undergo Repository your operate will get despatched to the Wolfram Operate Repository evaluation workforce, whose mandate is to make sure that features within the repository do what they are saying they do, work in a method that’s in step with normal Wolfram Language design ideas, have good names, and are adequately documented. Apart from very specialised features, the objective is to complete critiques inside every week (and generally significantly sooner)—and to publish features as quickly as they’re prepared.
There’s a digest of latest (and up to date) features within the Operate Repository that will get despatched out each Friday—and makes for attention-grabbing studying (you possibly can subscribe right here):

The Wolfram Operate Repository is a curated public useful resource that may be accessed from any Wolfram Language system (and, by the best way, the supply code for each operate is accessible—simply press the Supply Pocket book button). However there’s one other essential use case for the infrastructure of the Operate Repository: privately deployed “useful resource features”.
All of it works by way of the Wolfram Cloud. You utilize the very same Definition Pocket book, however now as a substitute of submitting to the general public Wolfram Operate Repository, you simply deploy your operate to the Wolfram Cloud. You can also make it non-public in order that solely you, or some particular group, can entry it. Or you can also make it public, so anybody who is aware of its URL can instantly entry and use it of their Wolfram Language system.
This seems to be a tremendously helpful mechanism, each for group initiatives, and for creating printed materials. In a way it’s a really light-weight however strong method to distribute code—packaged into features that may instantly be used. (By the best way, to search out the features you’ve printed out of your Wolfram Cloud account, simply go to the DeployedResources folder within the cloud file browser.)
(For organizations that need to handle their very own operate repository, it’s value mentioning that the entire Wolfram Operate Repository mechanism—together with the infrastructure for doing critiques, and so on.—can also be out there in a non-public kind by way of the Wolfram Enterprise Personal Cloud.)
So what’s within the public Wolfram Operate Repository? There are numerous “specialty features” meant for particular “area of interest” functions—however very helpful in the event that they’re what you need:





There are features that add varied sorts of visualizations:







Some features arrange consumer interfaces:

Some features hyperlink to exterior companies:




Some features present easy utilities:

There are additionally features which are being explored for potential inclusion within the core system:


There are additionally numerous “modern” features, added as a part of analysis or exploratory improvement. And for instance in items I write (together with this one), I make some extent of getting all footage and different output be backed by “click-to-copy” code that reproduces them—and this code very often accommodates features both from the general public Wolfram Operate Repository or from (publicly accessible) non-public deployments.
The Paclet Repository Arrives
Paclets are a expertise we’ve used for greater than a decade and a half to distribute up to date performance to Wolfram Language programs within the area. In Model 13 we started the method of offering instruments for anybody to create paclets. And since Model 13 we’ve launched the Wolfram Language Paclet Repository as a centralized repository for paclets:

What’s a paclet? It’s a set of Wolfram Language performance—together with operate definitions, documentation, exterior libraries, stylesheets, palettes and extra—that may be distributed as a unit, and instantly deployed in any Wolfram Language system.
The Paclet Repository is a centralized place the place anybody can publish paclets for public distribution. So how does this relate to the Wolfram Operate Repository? They’re curiously complementary—with totally different optimization and totally different setups. The Operate Repository is extra light-weight, the Paclet Repository extra versatile. The Operate Repository is for making out there particular person new features, that independently match into the entire current construction of the Wolfram Language. The Paclet Repository is for making out there larger-scale items of performance, that may outline a complete framework and setting of their very own.
The Operate Repository can also be totally curated, with each operate being reviewed by our workforce earlier than it’s posted. The Paclet Repository is an immediate-deployment system, with out pre-publication evaluation. Within the Operate Repository each operate is specified simply by its title—and our evaluation workforce is chargeable for guaranteeing that names are nicely chosen and haven’t any conflicts. Within the Paclet Repository, each contributor will get their very own namespace, and all their features and different materials dwell inside that namespace. So, for instance, I contributed the operate RandomHypergraph to the Operate Repository, which might be accessed simply as ResourceFunction["RandomHypergraph"]. But when I had put this operate in a paclet within the Paclet Repository, it must be accessed as one thing like PacletSymbol["StephenWolfram/Hypergraphs", "RandomHypergraph"].
PacletSymbol, by the best way, is a handy method of “deep accessing” particular person features inside a paclet. PacletSymbol briefly installs (and masses) a paclet with the intention to entry a specific image in it. However extra typically one desires to completely set up a paclet (utilizing PacletInstall), then explicitly load its contents (utilizing Wants) every time one desires to have its symbols out there. (All the assorted ancillary components, like documentation, stylesheets, and so on. in a paclet get arrange when it’s put in.)
What does a paclet appear to be within the Paclet Repository? Each paclet has a house web page that sometimes contains an total abstract, a information to the features within the paclet, and a few total examples of the paclet:

Particular person features sometimes have their very own documentation pages:

Similar to in the primary Wolfram Language documentation, there generally is a complete hierarchy of information pages, and there might be issues like tutorials.
Discover that in examples in paclet documentation, one typically sees constructs like ![]() . These signify symbols within the paclet, introduced in types like PacletSymbol["WolframChemistry/ProteinVisualization", "AmidePlanePlot"] that permit these symbols to be accessed in a “standalone” method. For those who immediately consider such a kind, by the best way, it’ll pressure (momentary) set up of the paclet, then return the precise, uncooked image that seems within the paclet:
. These signify symbols within the paclet, introduced in types like PacletSymbol["WolframChemistry/ProteinVisualization", "AmidePlanePlot"] that permit these symbols to be accessed in a “standalone” method. For those who immediately consider such a kind, by the best way, it’ll pressure (momentary) set up of the paclet, then return the precise, uncooked image that seems within the paclet:
So how does one create a paclet appropriate for submission to the Paclet Repository? You are able to do it purely programmatically, or you can begin from File > New > Repository Merchandise > Paclet Repository Merchandise, which launches what quantities to a complete paclet creation IDE. Step one is to specify the place you need to assemble your paclet. You give some fundamental info

then a Paclet Useful resource Definition Pocket book is created, from which you’ll be able to give operate definitions, arrange documentation pages, specify what you need your paclet’s residence web page to be like, and so on.:

There are many subtle instruments that allow you to create full-featured paclets with the identical sort of breadth and depth of capabilities that you simply discover within the Wolfram Language itself. For instance, Documentation Instruments permits you to assemble full-featured documentation pages (operate pages, information pages, tutorials, …):

When you’ve assembled a paclet, you possibly can verify it, construct it, deploy it privately—or submit it to the Paclet Repository. And when you submit it, it should routinely get arrange on the Paclet Repository servers, and inside only a few minutes the pages you’ve created describing your paclet will present up on the Paclet Repository web site.
So what’s within the Paclet Repository to date? There’s numerous good and really severe stuff, contributed each by groups at our firm and by members of the broader Wolfram Language group. Actually, most of the 134 paclets now within the Paclet Repository have sufficient in them that there’s a complete piece like this that one may write about them.
One class of belongings you’ll discover within the Paclet Repository are snapshots of our ongoing inside improvement initiatives—a lot of which is able to finally turn into built-in components of the Wolfram Language. An excellent instance of that is our LLM and Chat Pocket book performance, whose speedy improvement and deployment over the previous 12 months was made doable by means of the Paclet Repository. One other instance, representing ongoing work from our chemistry workforce (AKA WolframChemistry within the Paclet Repository) is the ChemistryFunctions paclet, which accommodates features like:

And, sure, that is interactive:

Or, additionally from WolframChemistry:

One other “improvement snapshot” is DiffTools—a paclet for making and viewing diffs between strings, cells, notebooks, and so on.:

A serious paclet is QuantumFramework—which offers the performance for our Wolfram Quantum Framework

and delivers broad help for quantum computing (with no less than a number of connections to multiway programs and our Physics Undertaking):


Speaking of our Physics Undertaking, there are over 200 features supporting it which are within the Wolfram Operate Repository. However there are additionally paclets, like WolframInstitute/Hypergraph:

An instance of an externally contributed bundle is Automata—with greater than 250 features for doing computations associated to finite automata:


One other contributed paclet is FunctionalParsers, which fits from a symbolic parser specification to an precise parser, right here being utilized in a reverse mode to generate random “sentences”:

Phi4Tools is a extra specialised paclet, for working with Feynman diagrams in ![]() area idea:
area idea:



And, as one other instance, right here’s MaXrd, for crystallography and x-ray scattering:


As only one extra instance, there’s the Organizer paclet—a utility paclet for making and manipulating organizer notebooks. However not like the opposite paclets we’ve seen right here, it doesn’t expose any Wolfram Language features; as a substitute, whenever you set up it, it places a palette in your Palettes checklist:


Coming Sights
As of right now, Model 14 is completed, and out on this planet. So what’s subsequent? Now we have numerous initiatives underway—some already with years of improvement behind them. Some prolong and strengthen what’s already within the Wolfram Language; some take it in new instructions.
One main focus is broadening and streamlining the deployment of the language: unifying the best way it’s delivered and put in on computer systems, packaging it so it may be effectively built-in into different standalone functions, and so on.
One other main focus is increasing the dealing with of very massive quantities of knowledge by the Wolfram Language—and seamlessly integrating out-of-core and lazy processing.
Then in fact there’s algorithmic improvement. Some is “classical”, immediately constructing on the towers of performance we’ve developed over the a long time. Some is extra “AI based mostly”. We’ve been creating heuristic algorithms and meta-algorithms ever since Model 1.0—more and more utilizing strategies from machine studying. How far will neural internet strategies go? We don’t know but. We’re routinely utilizing them in issues like algorithm choice. However to what extent can they assist in the guts of algorithms?
I’m reminded of one thing we did again in 1987 in creating Model 1.0. There was a protracted custom in numerical evaluation of painstakingly deriving collection approximations for explicit instances of mathematical features. However we wished to have the ability to compute a whole bunch of various features to arbitrary precision for any advanced values of their arguments. So how did we do it? We generalized from collection to rational approximations—after which, in a really “machine-learning-esque” method—we spent months of CPU time systematically optimizing these approximations. Effectively, we’ve been making an attempt to do the identical sort of factor once more—although now over extra bold domains—and now utilizing not rational features however massive neural nets as our foundation.
We’ve additionally been exploring utilizing neural nets to “management” exact algorithms, in impact making heuristic selections which both information or might be validated by the exact algorithms. To date, none of what we’ve produced has outperformed our current strategies, however it appears believable that pretty quickly it should.
We’re doing loads with varied points of metaprogramming. There’s the mission of
getting LLMs to assist in the development of Wolfram Language code—and in giving feedback on it, and in analyzing what went mistaken if the code didn’t do what one anticipated. Then there’s code annotation—the place LLMs could assist in doing issues like predicting the most definitely kind for one thing. And there’s code compilation. We’ve been working for a few years on a full-scale compiler for the Wolfram Language, and in each model what we’ve got turns into progressively extra succesful. We’ve been doing a little stage of automated compilation particularly instances (significantly ones involving numerical computation) for greater than 30 years. And finally full-scale automated compilation can be doable for the whole lot. However as of now a few of the largest payoffs from our compiler expertise have been for our inside improvement, the place we are able to now get optimum down-to-the-metal efficiency just by compiled (albeit rigorously written) Wolfram Language code.
One of many huge classes of the shocking success of LLMs is that there’s doubtlessly extra construction in significant human language than we thought. I’ve lengthy been eager about creating what I’ve known as a “symbolic discourse language” that offers a computational illustration of on a regular basis discourse. The LLMs haven’t explicitly finished that. However they encourage the concept that it ought to be doable, they usually additionally present sensible assist in doing it. And whether or not the objective is to have the ability to signify narrative textual content, or contracts, or textual specs, it’s a matter of extending the computational language we’ve constructed to embody extra sorts of ideas and buildings.
There are sometimes a number of sorts of drivers for our continued improvement efforts. Typically it’s a query of continuous to construct a tower of capabilities in some identified course (like, for instance, fixing PDEs). Typically the tower we’ve constructed immediately lets us see new prospects. Typically after we truly use what we’ve constructed we understand there’s an apparent method to polish or prolong it—or to “double down” on one thing that we are able to now see is effective. After which there are instances the place issues occurring within the expertise world immediately open up new prospects—like LLMs have just lately finished, and maybe XR will finally do. And at last there are instances the place new science-related insights counsel new instructions.
I had assumed that our Physics Undertaking would at greatest have sensible functions solely centuries therefore. However in truth it’s turn into clear that the correspondence it’s outlined between physics and computation provides us fairly quick new methods to consider points of sensible computation. And certainly we’re now actively exploring the right way to use this to outline a brand new stage of parallel and distributed computation within the Wolfram Language, in addition to to signify symbolically not solely the outcomes of computations but in addition the continuing technique of computation.
One may assume that after almost 4 a long time of intense improvement there wouldn’t be something left to do in creating the Wolfram Language. However in truth at each stage we attain, there’s ever extra that turns into doable, and ever extra that may we see is likely to be doable. And certainly this second is a very fertile one, with an unprecedentedly broad waterfront of prospects. Model 14 is a vital and satisfying waypoint. However there are great issues forward—as we proceed our long-term mission to make the computational paradigm obtain its potential, and to construct our computational language to assist that occur.
[ad_2]