
[ad_1]
This text was co-written by utilized analysis scientists Vipul Raheja and Dhruv Kumar.
Introduction
At Grammarly, we’re at all times exploring methods to make the writing and modifying course of higher. This has included intensive use of huge language fashions (LLMs), which bought us questioning: What if we made LLMs specialise in textual content modifying?
We’ve observed a niche in present analysis: LLMs are usually skilled for a broad set of text-generation duties. Nonetheless, for extra well-scoped duties like textual content modifying, instruction tuning generally is a very efficient strategy to construct higher-quality, smaller, and extra performant LLMs. These LLMs, in flip, could be higher-quality, clever writing assistants. This strategy includes refining a base LLM with a dataset of well-crafted examples, together with directions and corresponding textual content inputs and outputs, a course of often known as instruction fine-tuning. However critically, its success is determined by the standard of those educational examples.
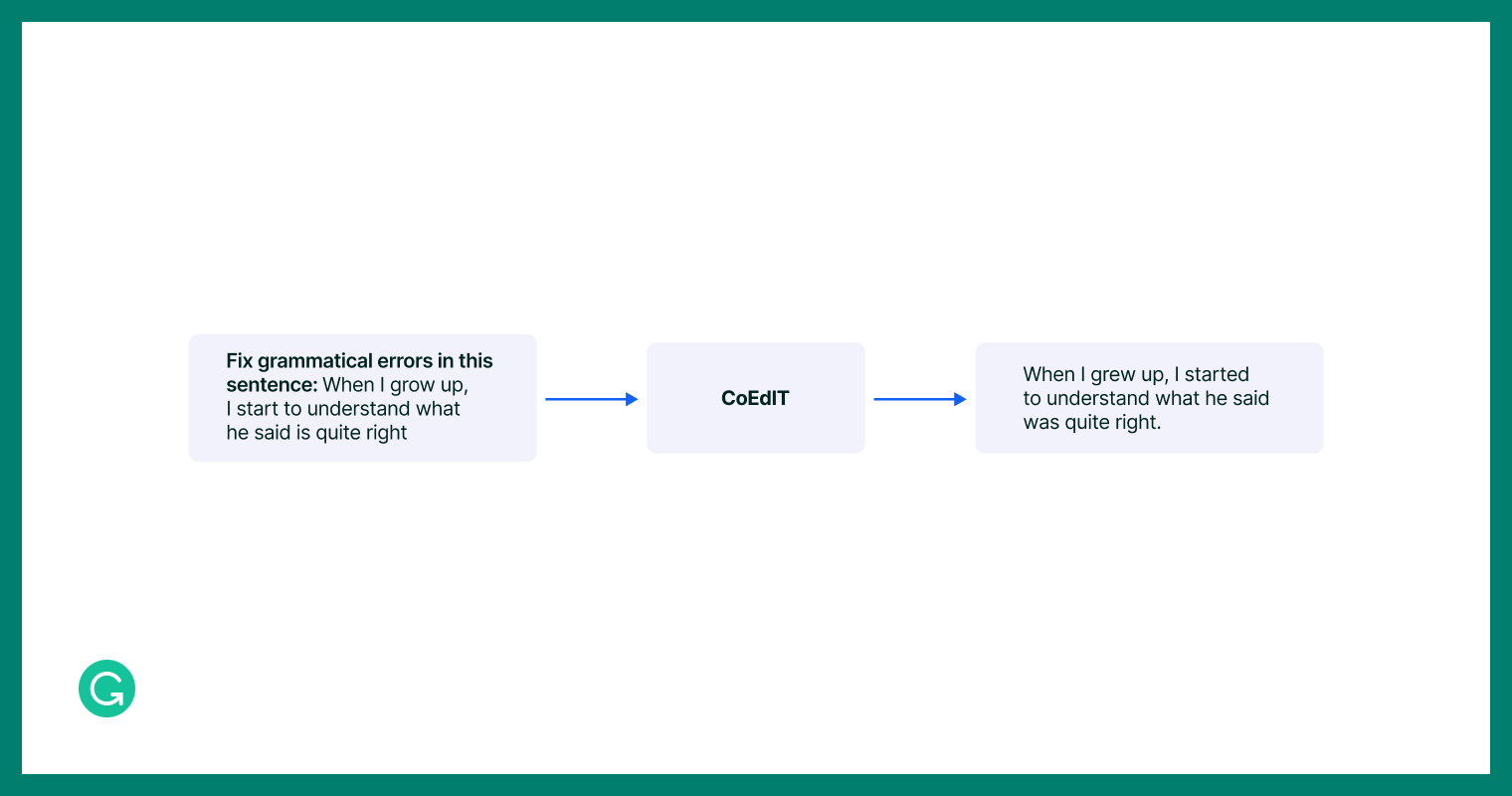
An instance of a single instruction-tuning information row.
So we compiled a dataset for instruction tuning on textual content modifying examples to construct CoEdIT, an instruction-tuned LLM for textual content modifying. CoEdIT is an open-source LLM that’s not solely as much as 60 occasions smaller than common LLMs like GPT-3-Edit (175 billion parameters) and ChatGPT, it additionally outperforms them on a variety of writing help duties. On this submit, we’ll summarize the outcomes from our paper, “CoEdIT: Textual content Modifying by Process-Particular Instruction Tuning,” which was accepted as a Findings paper on the 2023 Convention on Empirical Strategies in Pure Language Processing (EMNLP 2023). It was co-authored with our collaborators Ryan Koo and Dongyeop Kang (College of Minnesota) and constructed on our earlier work on IteraTeR: NLP Textual content Revision Dataset Era and DELIteraTeR, a Delineate-and-Edit Strategy to Iterative Textual content Revision. We’ll share how we constructed the CoEdIT fine-tuning dataset and the way we constructed and evaluated the CoEdIT fashions, all of that are publicly out there within the CoEdIT repository on GitHub.
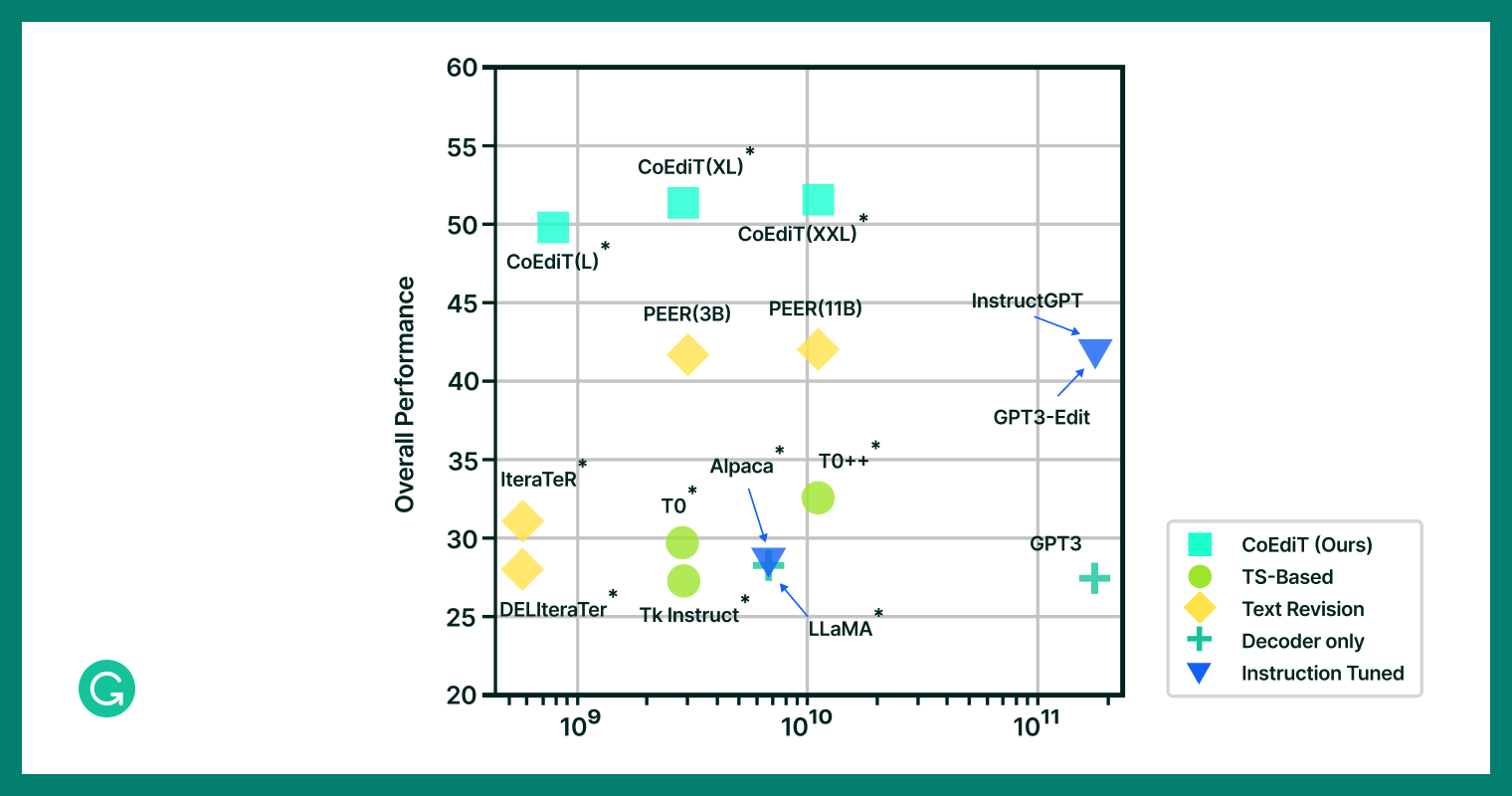
Mannequin efficiency versus dimension: bigger fashions notably fall quick in textual content modifying efficiency in comparison with CoEdIT.
What we did
On this work, we started by addressing a number of the gaps current in creating general-purpose textual content modifying fashions utilizing LLMs, as they considerably restricted mannequin effectiveness, efficiency, or usability:
- Lack of coaching with instruction tuning, which restricted their usability and interpretability
- Coaching on undersized fashions, which restricted their capabilities
- Not coaching on task-specific datasets (i.e., coaching on extremely common datasets), which restricted their high quality
- Lack of public availability (i.e., not open-source), which restricted their usability and reproducibility
We thought that fine-tuning LLMs utilizing textual content modifying duties, moderately than a broader record of common duties, may do quite a bit to handle the gaps we recognized. Normal duties characterize a “sparse process distribution”—something from “summarize this textual content’” to “translate this textual content to French,” that are each helpful however not very intently associated to 1 one other. We would consider a human that would deal with these duties as having a “generalist” talent set. However, a extra particular, or “dense,” process distribution would cowl duties which might be extra intently associated, like “paraphrase this textual content” and “make this textual content coherent.” In a human, we’d attribute a set of abilities like this to a textual content modifying specialist (i.e., an editor).
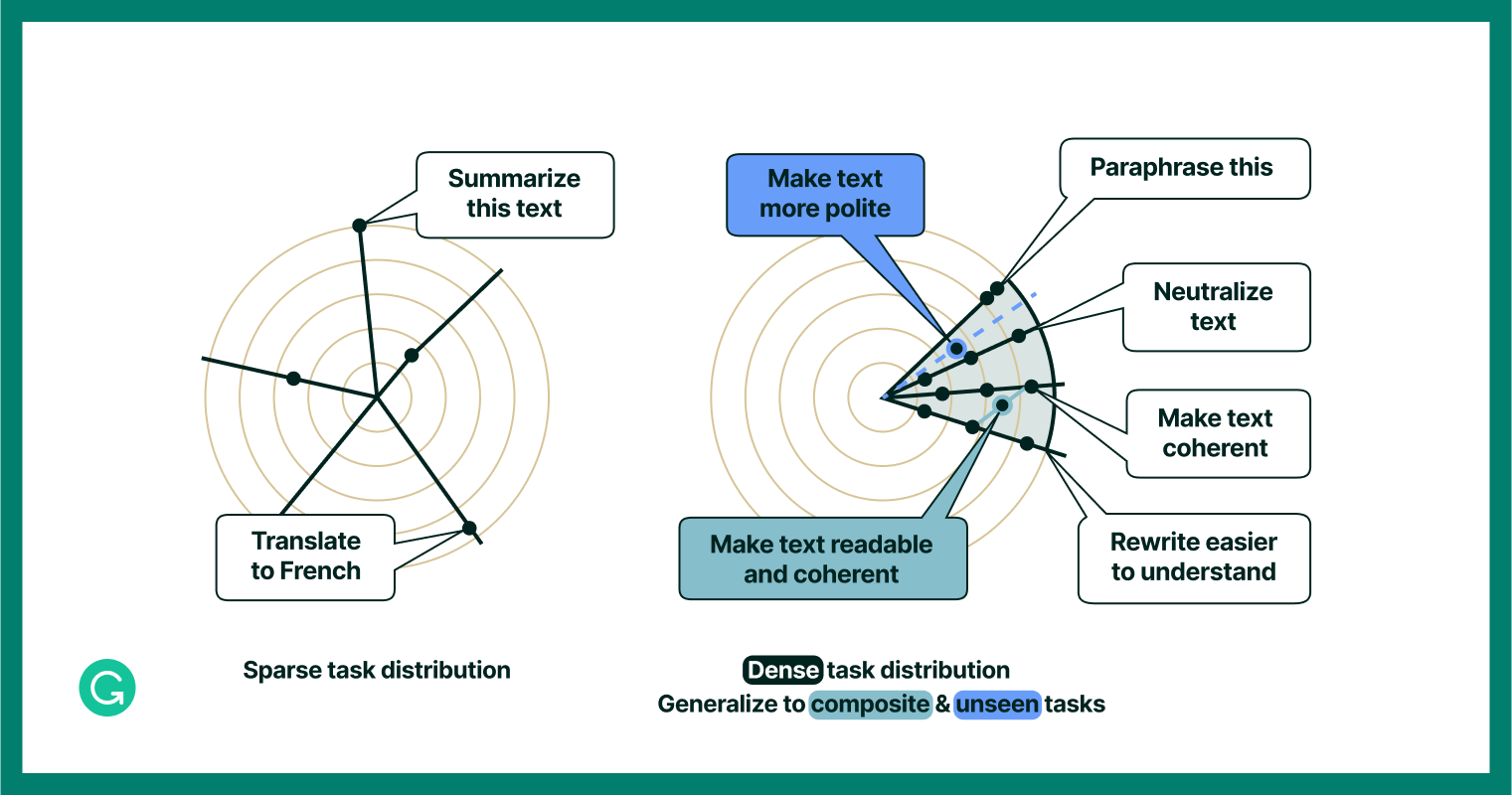
An illustrative instance of how dense coaching process distribution can result in higher generalization to composite and unseen duties.
The chance, then, was to make use of instruction tuning to show CoEdIT right into a textual content modifying specialist. And identical to a human specialist, we thought that performing nicely on “adjoining” duties—duties which might be near, however not precisely, its specialty—can be considerably simpler for CoEdIT than it might be for an LLM generalist.
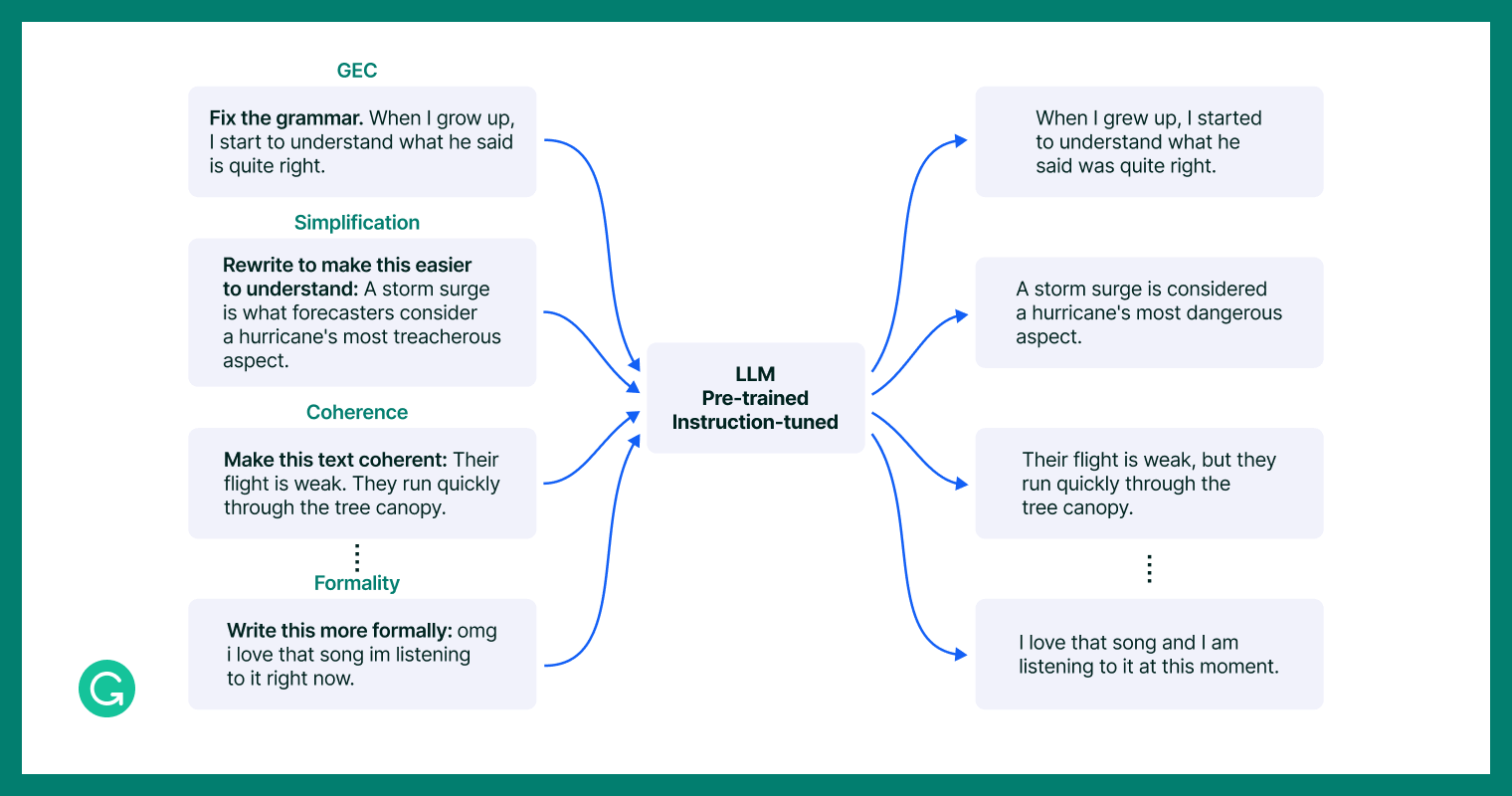
Instance duties that the instruction-tuned CoEdIT mannequin, as a “specialist” within the dense process house of textual content modifying, would possibly undertake extra successfully.
Constructing the coaching dataset
This begs the query: How would we obtain a dense textual content modifying process distribution for the CoEdIT dataset?
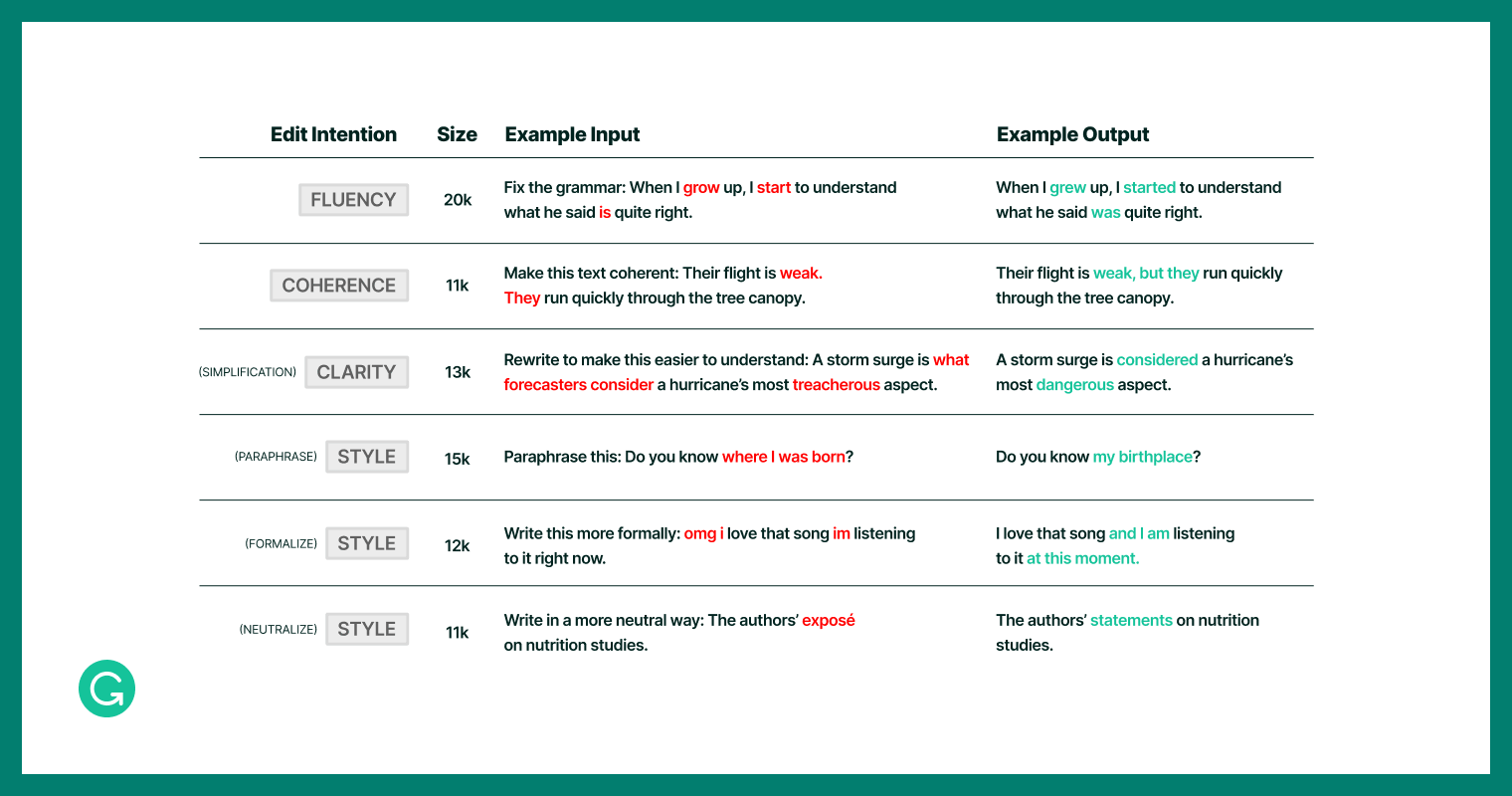
To assemble our dataset, we constructed upon the IteraTeR+ dataset1, which accommodates quite a lot of textual content modifying duties whereas specializing in non-meaning-changing edits. We translated edit classes—Fluency, Coherence, Readability, Type—into pure language directions, equivalent to “Make this extra coherent.” To attain consistency, significantly in subjective areas like type, we launched particular sub-intentions like Paraphrasing, Formality Type Switch, and Neutralization. Moreover, to verify our mannequin would perceive completely different phrasings of the identical precise instruction (i.e., “write” versus “rewrite” a sentence), we created paraphrases of instruction templates and added these to the dataset.
Coaching the mannequin
As soon as the work of making the dataset was full, we fine-tuned just a few completely different variations of a pre-trained FLANT5<sup>2</sup> LLM (L: 770 million parameters, XL: 3 billion parameters, XXL: 11 billion parameters) with the CoEdIT dataset. We named these fashions CoEdIT-L, CoEdIT-XL, and CoEdIT-XXL respectively.
Evaluating efficiency
Judging writing and edit high quality is a naturally subjective course of: Anybody author’s opinion would possibly differ from one other’s. However in a bigger mixture, there may be typically significant consensus.
Given this subjectivity, and the shortage of accepted quantitative measures for a number of the qualities we have been all in favour of, we devised each qualitative and quantitative benchmarks of how nicely CoEdIT carried out.
Fashions in contrast in opposition to
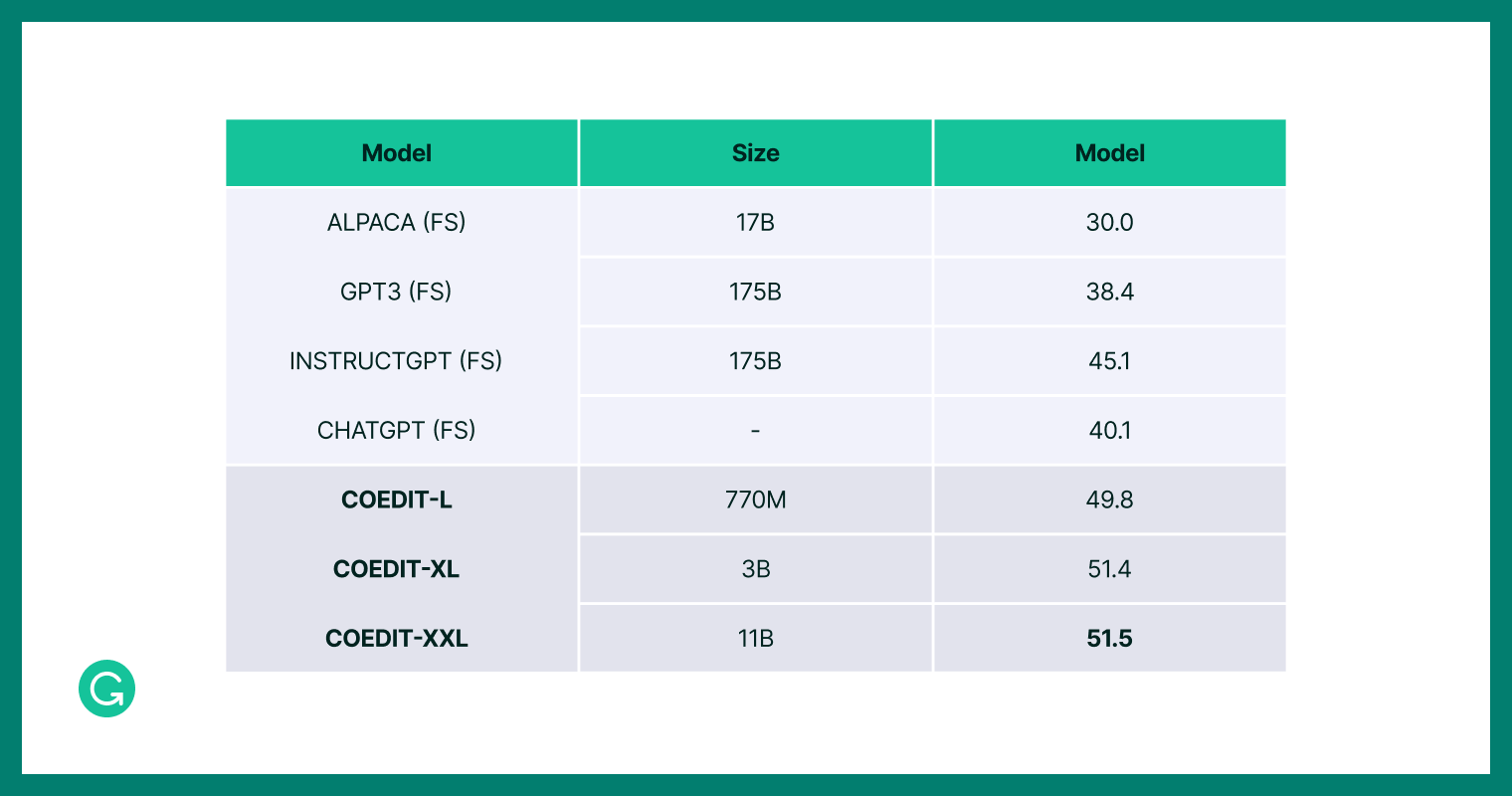
To determine simply how nicely CoEdIT did, we wanted one thing to match in opposition to. So, we devised 4 comparability teams:
- A no-edit baseline: Outputs are merely copies of the supply, with the instruction eliminated.
- Supervised textual content modifying fashions: Supervised fashions skilled on iterative textual content revision duties. See the IteraTeR Iterative Textual content Revision and DELIteraTeR, a Delineate-and-Edit Strategy to Iterative Textual content Revision Grammarly weblog posts for extra.
- Instruction-tuned LLMs: LLMs which were instruction-tuned, albeit on completely different instruction corpora than CoEdIT, like ChatGPT3 and GPT3-Edit4
- Decoder-only LLMs: LLMs with no instruction tuning, like GPT-35 and LLaMA6
To see the complete particulars of the fashions used, and the situations they have been evaluated in, please confer with the complete paper.
Quantitative evaluation
Representatives from every of those 4 comparability teams, together with CoEdIT, have been then evaluated in opposition to customary take a look at units from quite a lot of textual content modifying benchmarks7. We discovered that CoEdIT achieves state-of-the-art efficiency on a number of benchmark take a look at units, spanning syntactic, semantic, and stylistic edit necessities. However maybe equally attention-grabbing, we discovered that even our smallest mannequin, CoEdIT-L, outperforms different supervised textual content modifying fashions, instruction-tuned fashions, and general-purpose LLMs. And it does so with wherever between 12 occasions and 60 occasions fewer parameters on each automated and handbook evaluations.
Qualitative evaluation
To enrich our quantitative evaluation, we carried out human evaluations to grasp human notion and desire of edits generated by CoEdIT. Our knowledgeable evaluators in contrast the outputs of two fashions, CoEdIT-XL (3 billion) and GPT3-Edit (175 billion), for fluency, accuracy, and preservation of that means. The outcomes have been clear: Evaluators most popular CoEdIT’s output 64 p.c of the time, in comparison with simply 10 p.c for GPT3-Edit.
However we have been all in favour of extra than simply how CoEdIT carried out on acquainted duties. How would it not fare with “adjoining” duties it hadn’t encountered earlier than? We examined it with two associated duties that have been new to CoEdIT: sentence compression and politeness switch. On each, we discovered that CoEdIT outperformed rivals, together with GPT3-Edit. As we’d anticipated, CoEdIT was an knowledgeable at adapting to new duties associated to its textual content modifying specialty resulting from task-specific instruction tuning.
Evaluating efficiency on composite duties
Actual-world modifying duties typically contain modifying sequences, like “make the textual content less complicated, paraphrase it, and make it formal.” To evaluate CoEdIT’s aptitude for these “composite” modifying duties, we enriched its coaching set with multi-part duties, like “grammatical-error-correction with paraphrasing and simplification.” This led to the event of CoEdIT-Composite, skilled on this set of composite duties.
Within the absence of a benchmark for composite duties, human evaluators in contrast this new mannequin’s output with that of CoEdIT-XL and GPT3-Edit throughout the identical prompts. CoEdIT-Composite was most popular, outshining GPT3-Edit (38 p.c to 34 p.c) and the unique CoEdIT-XL (34 p.c to 21 p.c). Nonetheless, the nearer margins signaled alternatives for future enhancements, so we’re excited to proceed this promising line of analysis with composite-tuned CoEdIT.
Wanting ahead
It has been clear for a while that LLMs might be an unlimited support for clever writing help. CoEdIT makes this use case considerably extra accessible with its state-of-the-art efficiency, small dimension (as much as 60 occasions smaller than comparable performers), means to generalize to adjoining and composite modifying duties, and open-source fashions and information, which you’ll be able to entry within the CoEdIT repository.
With additional enhancements to our coaching strategies, we consider CoEdIT will be capable to assist with even bigger and extra complicated components of the modifying course of. This may embody enhancements like increasing its means to deal with longer texts, and higher accounting for immediate sensitivity in coaching and testing the mannequin, making CoEdIT an much more succesful natural-language-based writing assistant.
With analysis explorations like CoEdIT, along with our core product efforts, Grammarly stays dedicated to its mission of enhancing lives by enhancing communication. If that mission, and fixing issues like these, resonates, then we’ve excellent news: Grammarly’s NLP crew is hiring! We’re captivated with exploring and leveraging the potential of LLMs and generative AI to make writing and communication higher for everybody, and you may take a look at our open roles for extra data.
1 Kim et al. (2022)
2 Chung et al., 2022a
3 Utilizing OpenAI APIs for inference
4 GPT-3 additionally affords a textual content Modifying API (the “Edit API”, utilizing the text-davinci-edit-001 mannequin), referred to right here as GPT3-Edit, which is usable for modifying duties moderately than completion, making it immediately akin to the duties we skilled CoEdIT on.
5 Brown et al., 2020
6 Touvron et al., 2023
7 See the paper, part 4.2, for particulars on take a look at units and what they take a look at.
[ad_2]