
[ad_1]
Scientific knowledge in chemistry has come a good distance in the previous few a long time. Initially entangled into scientific articles within the type of tables of numbers or diagrams, it was (partially) disentangled into supporting info when journals turned digital within the late Nineties.[1] The subsequent section was the introduction of knowledge repositories within the early naughties. Now related to modern industrial firms resembling Figshare and later the non-commercial Zenodo, such repositories have additionally unfold to institutional type resembling eg the sooner SPECTRa challenge of 2006[2] and nonetheless evolving.[3] Maybe the perfect identified, and definitely one of many oldest examples of curated structural knowledge in chemistry is the CCDC (Cambridge crystallographic knowledge centre) CSD (Cambridge structural database) which has been working for greater than 55 years now, even earlier than the web period! Curation right here is the vital context, since there you’ll find crystal diffraction knowledge which has been refined right into a structural mannequin, firstly by the authors reporting the construction after which by CSD who amongst different operations, validate the related knowledge utilizing a utility known as CheckCIF.[4] What maybe will not be realised by most customers of this knowledge supply is that the unique or “uncooked” knowledge, as obtained from a X-ray diffractometer and which the CSD knowledge is derived from, will not be really accessible from the CSD. This main type of crystallographic knowledge is the subject of this submit.
Most chemical knowledge now emerges from an instrument, the place it’s already partially processed internally earlier than being provided. Such uncooked/main knowledge is probably finest identified within the type of NMR info, the place it’s provided by the instrument within the type of an FID or free induction decay. Its transformation from this kind into what all chemists know as a spectrum requires additional software program processing, and together with different operations resembling peak integration. It’s this processed spectrum that had historically been provided as a part of a scientific article (typically solely in visible, or peak listed type) and barely has the FID type been made accessible to anybody . You will need to state that the transformation to spectrum additionally incurrs vital lack of knowledge. An attention-grabbing challenge led by the editors of two natural chemistry journals[5],[6] had the intention of encouraging the submission of FAIR knowledge to the journal, though in reality the challenge really targeting the submission of uncooked NMR knowledge. Because it turned out, solely a really small proportion of all of the submissions to those journals over the interval of a yr really supplied such knowledge (~113 datasets) within the type of ZIP archives‡ and containing wherever between one and ~100 precise units of uncooked NMR knowledge per archive. One ought to make the purpose that uncooked knowledge will not be essentially FAIR knowledge. The latter requires wealthy metadata describing the information to change into findable, accessible, interoperable and reusable (FAIR), and such metadata was not really generated as a part of this writer challenge.
Right here I’ll take a better have a look at doubtlessly FAIR uncooked knowledge within the space of crystallography. This challenge is probably much less well-known than the earlier one,[5],[6] therefore the current submit strives to make it higher identified. As with NMR, a helpful start line is to explain the assorted levels within the lifecycle of crystal knowledge.
- A crystal is mounted within the diffractometer and x-ray diffraction photos are recorded. These are thought-about the uncooked knowledge, and as with most devices, their type is decided each by the instrument itself and the software program used to begin the refinement course of right into a molecular construction.
- This refinement then assigns an area group to the information and derives so-called construction components or hkl knowledge. This knowledge can now be captured in a way more commonplace type often called a CIF (crystallographic info file) and is these days the format that’s deposited with CSD.
- A decreased type of the CIF file, containing a sub-set of the knowledge however missing the hkl knowledge is way the extra widespread, and was the shape initially despatched to CSD till a number of years in the past.
- Fairly often a picture of the ensuing mannequin for the molecular construction can be included. While it’s primarily based on the information within the CIF file, it doesn’t comprise reusable knowledge as such and is taken into account as being made accessible just for human use and notion.
It’s type 1 that’s lacking from the CSD datasets. As a result of it may be fairly massive (~0.5-9 Gbyte), the present advice is that it isn’t saved on the CSD however on native knowledge repositories.† So now we see a necessity to determine if doable bidirectional hyperlinks between sort 1 and kinds 2-4 and to determine what traits of FAIR every has. Primarily, the F (findable) of FAIR can be explored right here. That is achieved by illustrating some searches for this knowledge, primarily based on the metadata registered for it with DataCite.
- https://commons.datacite.org/?question=relatedIdentifiers.relatedIdentifier:10.5517* (157 works)
This easy search identifies any entry in any repository which cites in its metadata document the DOI for an entry in CSD, taking the shape 10.5517* which is widespread to all entries. - ?question=relatedIdentifiers.relatedIdentifier:*10.5517*+AND+(media.media_type:chemical/x-cif+OR+media.media_type:software/x-7z-compressed+OR+media.media_type:software/gzip+OR+media.media_type:software/zip) (9 works).
This additionally specifies that search 5 is additional constrained by requiring one in all 4 media sorts to ALSO be current within the repository metadata document. These sorts are commonplace compressed archives which the uncooked crystal knowledge is prone to be saved as, together with a CIF entry that’s clearly related to crystal construction knowledge. The Boolean OR signifies that anybody of them could be current! One can now be a bit of extra sure that these entries comprise crystal construction knowledge. That we can’t be completely sure is clearly a present deficiency of the metadata current for the entries! - ?question=identifier:*10.5517*+AND+(relatedIdentifiers.relatedIdentifier:*10.14469*) (7 works)
Eight works from search 6 originate from a repository with the prefix 10.14469* and so now one can reverse the course and ask what number of are referenced within the metadata for every printed merchandise within the CSD? Round 945,473 entries within the CSD at the moment have a persistent DOI identifier related to them, all beginning with 10.5517* and so now one can seek for what number of of those additionally reference a associated identifier at 10.14469* Seven of them present up there. - Additionally within the CSD metadata information is an merchandise with the attribute relationType=”IsDerivedFrom” carrying the which means that the CSD knowledge is itself derived from (uncooked) knowledge held elsewhere. This info is captured in the course of the deposition course of with CCDC as per beneath.
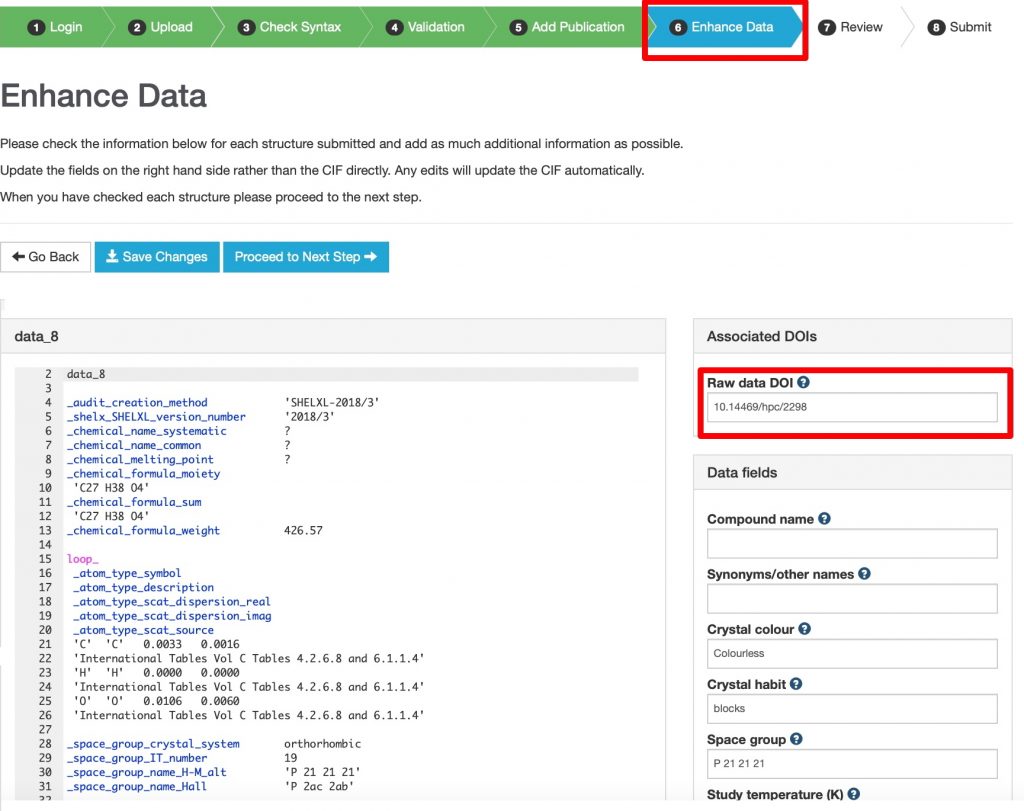
https://commons.datacite.org/?question=identifier:*10.5517*+AND+(relatedIdentifiers.relationType:IsSourceOf+OR+relatedIdentifiers.relationType:IsDerivedFrom) (7 works)
This constrains to datasets at CSD which might be related to extra uncooked knowledge by IsDerivedFrom or IsSourceOf relationships.♥ CCDC inform me the true quantity is round 65 so the origins of this mismatch have to be recognized.
So tasks aiming to seize knowledge from chemical instrumentation are simply beginning to reveal the potential of this contemporary system for storing knowledge in two or extra places and reconciling varied types of this knowledge, from uncooked type to derived or processed knowledge. The consumer can then use whichever type is most related to their wants, and having discovered one type can then hint again to the opposite type(s). We’d anticipate many developments on this space within the close to future.
‡One has to increase the archive to learn how many precise uncooked datasets are inside, fairly than figuring out beforehand what number of datasets are contained there, or anything about their properties. †The publication course of is described right here for one repository at DOI: 10.14469/hpc/10178 ♥From the DataCite schema; <relatedIdentifier relationType="IsDerivedFrom">... </relatedIdentifier> IsDerivedFrom ought to be used for a useful resource that could be a by-product of an authentic useful resource. On this instance, the dataset is derived from a bigger dataset and knowledge values have been manipulated from their authentic state. <relatedIdentifier relationType="IsSourceOf">... </relatedIdentifier> IsSourceOf is the unique useful resource from which a by-product useful resource was created. On this instance, that is the unique dataset with out worth manipulation.
This submit has DOI: 10.14469/hpc/10177
[ad_2]