
[ad_1]
Hariharan Narayanan, Scott Sheffield, and I’ve simply uploaded to the arXiv our paper “Sums of GUE matrices and focus of hives from correlation decay of eigengaps“. It is a personally satisfying paper for me, because it connects the work I did as a graduate pupil (with Allen Knutson and Chris Woodward) on sums of Hermitian matrices, with newer work I did (with Van Vu) on random matrix idea, in addition to a number of different outcomes by different authors scattered throughout varied mathematical subfields.
Suppose 

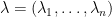
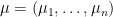
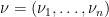
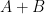
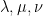

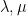



One in every of my favorite open issues is to give you a idea of “free hives” that enables one to clarify the latter reality from the previous. That is nonetheless unresolved, however we at the moment are starting to make a little bit of progress in the direction of this purpose. We all know (as an illustration from the calculations of Coquereaux and Zuber) that if 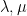
On this paper, we’re in a position to accomplish the primary half of this purpose, assuming that the spectra 

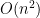
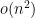
Augmented hives appear tough to work with straight, however by adapting the octahedron recurrence launched for this downside by Knutson, Woodward, and myself a while in the past (which is said to the associativity 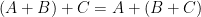
However, the piecewise linear map, initially outlined by iterating the octahedron relation 
It could be extra handy to review the focus of every linear map individually, somewhat than their supremum. By the Cheeger inequality, it seems that one can relate the latter to the previous supplied that one has good management on the Cheeger fixed of the underlying measure on the Gelfand-Tsetlin cones. Thankfully, the measure is log-concave, so one can use the very current work of Klartag on the KLS conjecture to remove the supremum (as much as a logarithmic loss which is just reasonably annoying to take care of).
It stays to acquire focus on the linear map related to a given lozenge tiling. After stripping away some contributions coming from lozenges close to the sting (utilizing some eigenvalue rigidity outcomes of Van Vu and myself), one is left with some bulk contributions which in the end contain eigenvalue interlacing gaps resembling
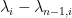
the place 

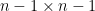



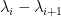
For this we turned to the work of Metcalfe, who uncovered a determinantal course of construction to this downside, with a kernel related to Lagrange interpolation polynomials. It’s attainable to satisfactorily estimate varied integrals of those kernels utilizing the residue theorem and eigenvalue rigidity estimates, thus finishing the required evaluation.
[ad_2]